he much publicized attack on Google’s computer systems in China earlier this year was directed by China’s Politburo, according to classified U.S. government documents released by the Web site WikiLeaks.org and reported today by several news organizations.
“The Google hacking was part of a coordinated campaign of computer sabotage carried out by government operatives, private security experts and Internet outlaws recruited by the Chinese government,” The New York Times reported.
This latest WikiLeaks release included thousands of communications between U.S. diplomats, their foreign counterparts and the U.S. State Department. A Chinese contact told the American Embassy in Beijing in January about the Politburo’s involvement in the Google case, the Times noted. This is additional detail not previously revealed about the role of the Chinese government, which has denied involvement.
In all, 34 companies were identified as having their computer systems hacked. Google reacted to the hacking by refusing to continue to censor Google search results in China on behalf of the government and directed visitors to its site that is based in Hong Kong. Google later backed down and had its Internet Content Provider license renewed by China. Visiting China.cn does not redirect to the Hong Kong site, though there is a link to Hong Kong on the Chinese Google site. Google has also restricted searches on Google.cn to " music, products and translation," according to PC World.
Computer security experts said at the time that one of the ways hackers were able to gain access to the Gmail accounts of human rights activists was by exploiting a vulnerability in Microsoft Windows computers, particularly in unpatched versions of the Internet Explorer 6 Web browser.
An additional review of diplomatic cables revealed that Chinese hackers have broken into American government computers and those of Western allies, the Dalai Lama and American businesses since 2002, according to the Times.
I have reported previously on this blog about the suspicions of cyber security experts of the duplicity of government officials in various countries, mainly China and Russia, in supporting or even just condoning cyber crime. Today we’ve got more proof of institutional involvement. The Poliburo is the governing body of the Communist Party of China.
Wednesday, December 15, 2010
U.S. tech lead at risk, says Obama's top scientist
U.S. Secretary of Energy Steven Chu, the only member of President Barack Obama's cabinet with a degree in a hard science, believes the U.S. is at risk of losing its leadership in technology as the nation's competitiveness deteriorates.
Chu, co-winner of the Nobel Prize in physics in 1997, used statistics and blunt language in a speech at the National Press Club in Washington Monday to point out that the U.S. lead in technology is declining and is in need of turnaround. He characterized the current situation as a " Sputnik moment " for the U.S., particularly in the area of clean energy development.
Chu illustrated his concern, in part, by describing the decline of the U.S. share of worldwide high technology manufacturing. The U.S. hit a peak in 1998 by capturing about 25% of the world's technology export market. The U.S. share has declined steadily since then to the current 12% to 13% of the global market.
Chart: Percentage of global high-tech exports from the U.S., EU and China.
The U.S. has developed "the greatest innovation machine" in the world, but Chu said that "today this leadership is at risk - we are no longer leaders in manufacturing, but more startling we are no longer the leaders in high technology manufacturing."
China has seen its global share of tech export market increase from 6% in 1995 to 20% in 2008, Chu said.
TechAmerica, an industry group, reported Tuesday that the overall value of tech exports fell 16% in 2009, from $223 billion in 2008 to $188 billion.
Josh James, vice president for research and industry analysis at TechAmerica, attributed last year's decline to the economic downturn. Otherwise, tech exports in the U.S. exports have been increasing. From 2003 to 2009, the value of U.S. tech exports increased by 13%, he said.
The U.S. overall increase in tech exports is due to rising global demand. TechAmerica produces the annual export report, in part, to help make a case that Congress should pass pending free trade agreements, this year with Columbia, Panama and South Korea.
High-tech exports account for nearly 1 million jobs in the U.S, he added.
Chu cited the role of some of U.S. technology developments, such as transistor, integrated circuit, GPS and the Internet, for the "wonderful things" they did to create wealth in the United States in past years. Similarly, Chu sees development of alternative energy vehicles, renewable energy, high speed rail and supercomputing, as important to maintaining U.S. technology leads.
Chu sought to dispel the idea that China is rapidly expanding its overall share of worldwide trade solely due to low cost labor.
He noted that China is expanding research and development efforts, citing Applied Materials opening last year of a 400,000 square foot solar research and development center there as an example.
The U.S. "still has the opportunity to lead in a world" in producing inexpensive, carbon free technology, and in doing so create a way to "secure our future prosperity," said Chu. "But I think time is running out." Chu believed the U.S. can maintain its leadership with investment and government policies that help drive these industries.
Chu, co-winner of the Nobel Prize in physics in 1997, used statistics and blunt language in a speech at the National Press Club in Washington Monday to point out that the U.S. lead in technology is declining and is in need of turnaround. He characterized the current situation as a " Sputnik moment " for the U.S., particularly in the area of clean energy development.
Chu illustrated his concern, in part, by describing the decline of the U.S. share of worldwide high technology manufacturing. The U.S. hit a peak in 1998 by capturing about 25% of the world's technology export market. The U.S. share has declined steadily since then to the current 12% to 13% of the global market.
Chart: Percentage of global high-tech exports from the U.S., EU and China.
The U.S. has developed "the greatest innovation machine" in the world, but Chu said that "today this leadership is at risk - we are no longer leaders in manufacturing, but more startling we are no longer the leaders in high technology manufacturing."
China has seen its global share of tech export market increase from 6% in 1995 to 20% in 2008, Chu said.
TechAmerica, an industry group, reported Tuesday that the overall value of tech exports fell 16% in 2009, from $223 billion in 2008 to $188 billion.
Josh James, vice president for research and industry analysis at TechAmerica, attributed last year's decline to the economic downturn. Otherwise, tech exports in the U.S. exports have been increasing. From 2003 to 2009, the value of U.S. tech exports increased by 13%, he said.
The U.S. overall increase in tech exports is due to rising global demand. TechAmerica produces the annual export report, in part, to help make a case that Congress should pass pending free trade agreements, this year with Columbia, Panama and South Korea.
High-tech exports account for nearly 1 million jobs in the U.S, he added.
Chu cited the role of some of U.S. technology developments, such as transistor, integrated circuit, GPS and the Internet, for the "wonderful things" they did to create wealth in the United States in past years. Similarly, Chu sees development of alternative energy vehicles, renewable energy, high speed rail and supercomputing, as important to maintaining U.S. technology leads.
Chu sought to dispel the idea that China is rapidly expanding its overall share of worldwide trade solely due to low cost labor.
He noted that China is expanding research and development efforts, citing Applied Materials opening last year of a 400,000 square foot solar research and development center there as an example.
The U.S. "still has the opportunity to lead in a world" in producing inexpensive, carbon free technology, and in doing so create a way to "secure our future prosperity," said Chu. "But I think time is running out." Chu believed the U.S. can maintain its leadership with investment and government policies that help drive these industries.
Thursday, July 8, 2010
Why Projects Management Fails?
Why Projects Management Fails?
Poor planning
Unclear goals and objectives
Objectives changing during the project
Wrong resource estimates
Lack of executive support and user involvement
Failure to communicate and act as a team
Inappropriate skills
Poor planning
Unclear goals and objectives
Objectives changing during the project
Wrong resource estimates
Lack of executive support and user involvement
Failure to communicate and act as a team
Inappropriate skills
As A Project Manager Which Situation You Think is Worse?
As A Project Manager Which Situation You Think is Worse?
.Successfully building and implementing a system that provides little or no value to the organization.
Or…
.Failing to implement an information system that could have provided value to the organization, but was poorly developed or poorly managed.
.Successfully building and implementing a system that provides little or no value to the organization.
Or…
.Failing to implement an information system that could have provided value to the organization, but was poorly developed or poorly managed.
Why do we need project management techniques?
Why do we need project management techniques?
.Clear work descriptions
.Minimize surprises and conflicts
.Responsibilities and assignments for specific tasks are easily identified
.Progress can be measured against a plan
.Clear work descriptions
.Minimize surprises and conflicts
.Responsibilities and assignments for specific tasks are easily identified
.Progress can be measured against a plan
Google wants to patent technology used to 'snoop' Wi-Fi networks
Google wants to patent technology used to 'snoop' Wi-Fi networks
lawyers in class-action suit link patent application to Street View data sniffing
Google's secret Wi-Fi snooping was powered by new sniffing technology that the company wants to patent, court documents filed Wednesday alleged.
A just-amended complaint in a class-action lawsuit first submitted two weeks ago claims that a patent Google submitted to the U.S. Patent and Trademark Office in November 2008 shows that the search giant purposefully created technology to gather, analyze and use data sent by users over their wireless networks. The lawsuit, which was filed by an Oregon woman and a Washington man in a Portland, Ore. federal court May 17, accused Google of violating federal privacy and data acquisition laws when its Street View vehicles snatched data from unprotected Wi-Fi networks as they drove up and down U.S. streets.
Google acknowledged the privacy issue May 14, but said it had not known it was collecting data from unprotected wireless networks until recently.
Lawyers for the plaintiffs in the Oregon lawsuit upped the ante Wednesday when they amended the original lawsuit to include charges that Google filed for a patent on Wi-Fi sniffing technology more than a year and a half ago.
According to the modified complaint, Google's technology can collect the make and model of wireless routers, the street address of that router and even the "approximate location of the wireless AP [access point] within the user's residence or business."
In its patent application , Google noted that multiple antennas could be mounted on vehicles, which would be able to obtain a more accurate estimate of the router's location based on a "stereo" effect.
Google has admitted that it sniffed basic wireless network information -- including the network and router identifiers -- to map those networks, which would then be used by mobile devices such as smartphones to pinpoint their locations in Google's mapping services. Google has claimed, however, that the code which grabbed data from unsecured Wi-Fi networks was added to the Street View vehicles data sniffers by mistake.
But the plaintiffs' lawyers said Google's patent application showed that the company's Wi-Fi locating technology had more in mind than just basic information.
"As disclosed in the '776 Application, the more types and greater the quantity of Wi-Fi data obtained, decoded, and analyzed by Google from any particular user, the higher its 'confidence level' in the calculated location of that user's wireless AP," the changed lawsuit stated. "Collection, decoding, and analysis of a user's payload data would, therefore, serve to increase the accuracy, value, usability, and marketability of Google's new method."
"Payload data" is the term given to the information transmitted over wireless networks, including the data that Google said it unintentionally snatched from the air as its Street View cars and trucks drove by homes and businesses.
lawyers in class-action suit link patent application to Street View data sniffing
Google's secret Wi-Fi snooping was powered by new sniffing technology that the company wants to patent, court documents filed Wednesday alleged.
A just-amended complaint in a class-action lawsuit first submitted two weeks ago claims that a patent Google submitted to the U.S. Patent and Trademark Office in November 2008 shows that the search giant purposefully created technology to gather, analyze and use data sent by users over their wireless networks. The lawsuit, which was filed by an Oregon woman and a Washington man in a Portland, Ore. federal court May 17, accused Google of violating federal privacy and data acquisition laws when its Street View vehicles snatched data from unprotected Wi-Fi networks as they drove up and down U.S. streets.
Google acknowledged the privacy issue May 14, but said it had not known it was collecting data from unprotected wireless networks until recently.
Lawyers for the plaintiffs in the Oregon lawsuit upped the ante Wednesday when they amended the original lawsuit to include charges that Google filed for a patent on Wi-Fi sniffing technology more than a year and a half ago.
According to the modified complaint, Google's technology can collect the make and model of wireless routers, the street address of that router and even the "approximate location of the wireless AP [access point] within the user's residence or business."
In its patent application , Google noted that multiple antennas could be mounted on vehicles, which would be able to obtain a more accurate estimate of the router's location based on a "stereo" effect.
Google has admitted that it sniffed basic wireless network information -- including the network and router identifiers -- to map those networks, which would then be used by mobile devices such as smartphones to pinpoint their locations in Google's mapping services. Google has claimed, however, that the code which grabbed data from unsecured Wi-Fi networks was added to the Street View vehicles data sniffers by mistake.
But the plaintiffs' lawyers said Google's patent application showed that the company's Wi-Fi locating technology had more in mind than just basic information.
"As disclosed in the '776 Application, the more types and greater the quantity of Wi-Fi data obtained, decoded, and analyzed by Google from any particular user, the higher its 'confidence level' in the calculated location of that user's wireless AP," the changed lawsuit stated. "Collection, decoding, and analysis of a user's payload data would, therefore, serve to increase the accuracy, value, usability, and marketability of Google's new method."
"Payload data" is the term given to the information transmitted over wireless networks, including the data that Google said it unintentionally snatched from the air as its Street View cars and trucks drove by homes and businesses.
Hackers exploit Windows XP zero-day, Microsoft confirms
Hackers exploit Windows XP zero-day, Microsoft confirms
Hackers are now exploiting the zero-day Windows vulnerability that a Google engineer took public last week, Microsoft confirmed today.
Although Microsoft did not share details of the attack, other researchers filled in the blanks.
A compromised Web site is serving an exploit of the bug in Windows' Help and Support Center to hijack PCs running Windows XP, said Graham Cluley, a senior technology consultant at antivirus vendor Sophos. Cluley declined to identify the site, saying only that it was dedicated to open-source software.
"It's a classic drive-by attack," said Cluley, referring to an attack that infects a PC when its user simply visits a malicious or compromised site. The tactic was one of two that Microsoft said last week were the likely attack avenues. The other: Convincing users to open malicious e-mail messages.
According to Microsoft, the exploit has since been scrubbed from the hacked Web site, but it expects more to surface. "We do anticipate future exploitation given the public disclosure of full details of the issue," said Jerry Bryant. Microsoft's group manager of response communications.
The vulnerability was disclosed last Thursday by Tavis Ormandy, a security engineer who works for Google . Ormandy, who also posted proof-of-concept attack code, defended his decision to reveal the flaw only five days after reporting it to Microsoft -- a move that Microsoft and other researchers questioned.
Today, Cluley called Ormandy's action "utterly irresponsible," and in a blog post asked, "Tavis Ormandy -- are you pleased with yourself?"
The five-day stretch between the day Ormandy reported the bug to Microsoft and when he publicly disclosed the flaw stuck in Cluley's craw. "Five days isn't enough time to expect Microsoft to develop a fix, which has to be tested thoroughly to ensure it doesn't cause more problems than it intends to correct," Cluley said.
In a message on Twitter last week, Ormandy said that he released the information because Microsoft would not commit to producing a patch within 60 days. "I'm getting pretty tired of all the '5 days' hate mail. Those five days were spent trying to negotiate a fix within 60 days," Ormandy said on Saturday .
Microsoft confirmed that its security team had discussed a patch schedule with Ormandy.
"We were in the early phases of the investigation and communicated [to him] on 6/7 that we would not know what our release schedule would be until the end of the week," said Bryant. "We were surprised by the public release of details on the 9th."
Microsoft issued a security advisory on the vulnerability last Thursday that acknowledged the bug and offered up a manual workaround it said would protect users against attack. The next day, it posted a "Fix it" tool that automatically unregisters the HCP protocol handler, a move Microsoft said "would help block known attack vectors before a security update is available."
The in-the-wild attack code is very similar to the proof-of-concept that Ormandy published last week, said Cluley.
Hackers are now exploiting the zero-day Windows vulnerability that a Google engineer took public last week, Microsoft confirmed today.
Although Microsoft did not share details of the attack, other researchers filled in the blanks.
A compromised Web site is serving an exploit of the bug in Windows' Help and Support Center to hijack PCs running Windows XP, said Graham Cluley, a senior technology consultant at antivirus vendor Sophos. Cluley declined to identify the site, saying only that it was dedicated to open-source software.
"It's a classic drive-by attack," said Cluley, referring to an attack that infects a PC when its user simply visits a malicious or compromised site. The tactic was one of two that Microsoft said last week were the likely attack avenues. The other: Convincing users to open malicious e-mail messages.
According to Microsoft, the exploit has since been scrubbed from the hacked Web site, but it expects more to surface. "We do anticipate future exploitation given the public disclosure of full details of the issue," said Jerry Bryant. Microsoft's group manager of response communications.
The vulnerability was disclosed last Thursday by Tavis Ormandy, a security engineer who works for Google . Ormandy, who also posted proof-of-concept attack code, defended his decision to reveal the flaw only five days after reporting it to Microsoft -- a move that Microsoft and other researchers questioned.
Today, Cluley called Ormandy's action "utterly irresponsible," and in a blog post asked, "Tavis Ormandy -- are you pleased with yourself?"
The five-day stretch between the day Ormandy reported the bug to Microsoft and when he publicly disclosed the flaw stuck in Cluley's craw. "Five days isn't enough time to expect Microsoft to develop a fix, which has to be tested thoroughly to ensure it doesn't cause more problems than it intends to correct," Cluley said.
In a message on Twitter last week, Ormandy said that he released the information because Microsoft would not commit to producing a patch within 60 days. "I'm getting pretty tired of all the '5 days' hate mail. Those five days were spent trying to negotiate a fix within 60 days," Ormandy said on Saturday .
Microsoft confirmed that its security team had discussed a patch schedule with Ormandy.
"We were in the early phases of the investigation and communicated [to him] on 6/7 that we would not know what our release schedule would be until the end of the week," said Bryant. "We were surprised by the public release of details on the 9th."
Microsoft issued a security advisory on the vulnerability last Thursday that acknowledged the bug and offered up a manual workaround it said would protect users against attack. The next day, it posted a "Fix it" tool that automatically unregisters the HCP protocol handler, a move Microsoft said "would help block known attack vectors before a security update is available."
The in-the-wild attack code is very similar to the proof-of-concept that Ormandy published last week, said Cluley.
Wednesday, July 7, 2010
Microsoft's cloud is slower than Google's, Amazon's,
Microsoft's cloud is slower than Google's, Amazon's, benchmark says
Over the past month, App Engine was speedier than both Azure and EC2, but Azure is fighting back.
Over the past month, Google's cloud, App Engine, performed faster than all of the other major clouds, including Microsoft's Azure. Azure was also consistently slower than at least one of Amazon's EC2 data centers, according to a live benchmarking service known as CloudSleuth.com.
Ironically, I was poking into cloud benchmarking hoping to learn that Microsoft Azure was faster than both Amazon and Google. I learned about the CloudSleuth.com from a blog post on MSDN when a Microsoft employee was bragging that Azure was outperforming the others this week. That result must have been a blip in the data because as I sliced the data, Azure never landed on top.
Google's average was about 1 second faster than Azure's, at least for the last 30 days.
CloudSleuth was created as a free online service by Compuware. These are the same folks that built the Gomez benchmarking tests that monitor Web app performance metrics such as comparing the same Web site loading into different browsers. (Compuware is a vendor of application performance monitoring tools.) Ergo, CloudSleuth uses the Gomez Performance Network (GPN) to measure the performance of an identical sample application running on several popular cloud service providers.
One day soon, CloudSleuth hopes to let users upload and compare their own cloud app to be benchmarked across the participating cloud vendors.
While playing with this site, I noticed that in the past few hours and days, Azure has been performing faster than all the other clouds except OpSource. (By the way, CloudSleuth names OpSource as a partner, though I can't say that this partnership affects the benchmarking results. The 30-day result clearly showed Google App Engine as faster than OpSource, but much of the time, OpSource lands on top.)
CloudSleuth shares all the details about the app used to benchmark the tests. It uses the default recommended configurations for each cloud service, although there are inherent differences between "old fashioned" hosting providers today known as Infrastructure as a Service (IaaS) and Platform as a Service providers (PaaS) which includes Azure and App Engine. The sample app is an e-commerce Web site.
Speed isn't the only consideration when comparing cloud services. But it is interesting to see that during any given period, an IaaS isn't always faster than a PaaS and vice versa.
Over the past month, App Engine was speedier than both Azure and EC2, but Azure is fighting back.
Over the past month, Google's cloud, App Engine, performed faster than all of the other major clouds, including Microsoft's Azure. Azure was also consistently slower than at least one of Amazon's EC2 data centers, according to a live benchmarking service known as CloudSleuth.com.
Ironically, I was poking into cloud benchmarking hoping to learn that Microsoft Azure was faster than both Amazon and Google. I learned about the CloudSleuth.com from a blog post on MSDN when a Microsoft employee was bragging that Azure was outperforming the others this week. That result must have been a blip in the data because as I sliced the data, Azure never landed on top.
Google's average was about 1 second faster than Azure's, at least for the last 30 days.
CloudSleuth was created as a free online service by Compuware. These are the same folks that built the Gomez benchmarking tests that monitor Web app performance metrics such as comparing the same Web site loading into different browsers. (Compuware is a vendor of application performance monitoring tools.) Ergo, CloudSleuth uses the Gomez Performance Network (GPN) to measure the performance of an identical sample application running on several popular cloud service providers.
One day soon, CloudSleuth hopes to let users upload and compare their own cloud app to be benchmarked across the participating cloud vendors.
While playing with this site, I noticed that in the past few hours and days, Azure has been performing faster than all the other clouds except OpSource. (By the way, CloudSleuth names OpSource as a partner, though I can't say that this partnership affects the benchmarking results. The 30-day result clearly showed Google App Engine as faster than OpSource, but much of the time, OpSource lands on top.)
CloudSleuth shares all the details about the app used to benchmark the tests. It uses the default recommended configurations for each cloud service, although there are inherent differences between "old fashioned" hosting providers today known as Infrastructure as a Service (IaaS) and Platform as a Service providers (PaaS) which includes Azure and App Engine. The sample app is an e-commerce Web site.
Speed isn't the only consideration when comparing cloud services. But it is interesting to see that during any given period, an IaaS isn't always faster than a PaaS and vice versa.
Monday, May 24, 2010
Facebook founder and CEO responds to complaints, introduces new settings
By Mark Zuckerberg
Six years ago, we built Facebook around a few simple ideas. People want to share and stay connected with their friends and the people around them. If we give people control over what they share, they will want to share more. If people share more, the world will become more open and connected. And a world that's more open and connected is a better world. These are still our core principles today.
Facebook has been growing quickly. It has become a community of more than 400 million people in just a few years. It's a challenge to keep that many people satisfied over time, so we move quickly to serve that community with new ways to connect with the social Web and each other. Sometimes we move too fast — and after listening to recent concerns, we're responding.
The challenge is how a network like ours facilitates sharing and innovation, offers control and choice, and makes this experience easy for everyone. These are issues we think about all the time. Whenever we make a change, we try to apply the lessons we've learned along the way. The biggest message we have heard recently is that people want easier control over their information. Simply put, many of you thought our controls were too complex. Our intention was to give you lots of granular controls; but that may not have been what many of you wanted. We just missed the mark.
We have heard the feedback. There needs to be a simpler way to control your information. In the coming weeks, we will add privacy controls that are much simpler to use. We will also give you an easy way to turn off all third-party services. We are working hard to make these changes available as soon as possible. We hope you'll be pleased with the result of our work and, as always, we'll be eager to get your feedback.
We have also heard that some people don't understand how their personal information is used and worry that it is shared in ways they don't want. I'd like to clear that up now. Many people choose to make some of their information visible to everyone so people they know can find them on Facebook. We already offer controls to limit the visibility of that information and we intend to make them even stronger.
Here are the principles under which Facebook operates:
You have control over how your information is shared.
We do not share your personal information with people or services you don't want.
We do not give advertisers access to your personal information.
We do not and never will sell any of your information to anyone.
We will always keep Facebook a free service for everyone.
Facebook has evolved from a simple dorm-room project to a global social network connecting millions of people. We will keep building, we will keep listening and we will continue to have a dialogue with everyone who cares enough about Facebook to share their ideas. And we will keep focused on achieving our mission of giving people the power to share and making the world more open and connected.
The writer is founder and chief executive of Facebook. Washington Post Chairman Donald E. Graham is a member of Facebook's board of directors.
Six years ago, we built Facebook around a few simple ideas. People want to share and stay connected with their friends and the people around them. If we give people control over what they share, they will want to share more. If people share more, the world will become more open and connected. And a world that's more open and connected is a better world. These are still our core principles today.
Facebook has been growing quickly. It has become a community of more than 400 million people in just a few years. It's a challenge to keep that many people satisfied over time, so we move quickly to serve that community with new ways to connect with the social Web and each other. Sometimes we move too fast — and after listening to recent concerns, we're responding.
The challenge is how a network like ours facilitates sharing and innovation, offers control and choice, and makes this experience easy for everyone. These are issues we think about all the time. Whenever we make a change, we try to apply the lessons we've learned along the way. The biggest message we have heard recently is that people want easier control over their information. Simply put, many of you thought our controls were too complex. Our intention was to give you lots of granular controls; but that may not have been what many of you wanted. We just missed the mark.
We have heard the feedback. There needs to be a simpler way to control your information. In the coming weeks, we will add privacy controls that are much simpler to use. We will also give you an easy way to turn off all third-party services. We are working hard to make these changes available as soon as possible. We hope you'll be pleased with the result of our work and, as always, we'll be eager to get your feedback.
We have also heard that some people don't understand how their personal information is used and worry that it is shared in ways they don't want. I'd like to clear that up now. Many people choose to make some of their information visible to everyone so people they know can find them on Facebook. We already offer controls to limit the visibility of that information and we intend to make them even stronger.
Here are the principles under which Facebook operates:
You have control over how your information is shared.
We do not share your personal information with people or services you don't want.
We do not give advertisers access to your personal information.
We do not and never will sell any of your information to anyone.
We will always keep Facebook a free service for everyone.
Facebook has evolved from a simple dorm-room project to a global social network connecting millions of people. We will keep building, we will keep listening and we will continue to have a dialogue with everyone who cares enough about Facebook to share their ideas. And we will keep focused on achieving our mission of giving people the power to share and making the world more open and connected.
The writer is founder and chief executive of Facebook. Washington Post Chairman Donald E. Graham is a member of Facebook's board of directors.
Wednesday, May 19, 2010
Microsoft counters Gmail with Hotmail overhaul
Microsoft is trying to counter Google by overhauling Windows Live Hotmail with new online editing capabilities for Office documents, and more than two dozen other enhancements for business and home users.
Microsoft's refresh of Hotmail is being announced Tuesday, less than a week after the release of Microsoft Office 2010
Microsoft strikes blow against Google with Office 2010
"The moment you receive an Office document as an attachment in Hotmail - Word, Excel or PowerPoint - you can open and view the attachment online in any popular browser, on PC or Mac and even if Office is not installed," Microsoft said in its latest announcement. "This results from the seamless integration between Hotmail, SkyDrive [Microsoft's free online storage service] and the Office Web Apps, so you can send, receive and work on a document with others."
Google, of course, offers online editing of documents through Gmail's integration with Google Docs, and the ability to import Microsoft Office documents into Google's online office suite.
Microsoft is increasingly adding to its lineup of Web-based office tools, while offering integration with existing on-premise software installations of Microsoft Office.
New Hotmail features announced this week will be incorporated into the service over the next few months, Microsoft said.
Microsoft promised improvements in the visual quality of Office documents displayed in web browsers, and said it will be easy for users to move back and forth between the Web-based version and the Office software installed on their PCs.
The announcement acknowledges that users may still need to use the packaged software version of Office for "intensive editing tasks."
"If you need to perform intensive editing tasks, you can go from editing the document in your browser with the Office Web Apps to editing it in an Office application on your PC," Microsoft said. "When you're finished, any edits you made to the document on your PC will be automatically saved back into the cloud where you can then keep the document stored for only you to see or share it with others."
Hotmail and Gmail are locked in a battle for second place in the webmail market. Each have more than 40 million users in the United States, with Hotmail claiming a small lead over Gmail. Yahoo still has more than twice as many users as its nearest competitors.
In addition to further Office integration, Microsoft said the new Hotmail will have enhanced security with full-session SSL; smarter junk mail filters and a "Trusted Senders" feature making it easier for users to distinguish between legitimate messages and scams.
Hotmail will also have conversation view – a feature Gmail already has – making it easier to view a single conversation that is spread out over many e-mails.
Hotmail users will be able to send up to 10GB of photos per message, and Microsoft, not surprisingly, is rolling out new mobile features to take advantage of the expanding smartphone market. For example, Microsoft said Hotmail will be optimized for rich mobile browsers and touch screens, while supporting "filters, in-line message previews, HTML messages, offline e-mail viewing, conversation threading, the ability to flag messages, the option to turn header details on or off, and more."
Microsoft's refresh of Hotmail is being announced Tuesday, less than a week after the release of Microsoft Office 2010
Microsoft strikes blow against Google with Office 2010
"The moment you receive an Office document as an attachment in Hotmail - Word, Excel or PowerPoint - you can open and view the attachment online in any popular browser, on PC or Mac and even if Office is not installed," Microsoft said in its latest announcement. "This results from the seamless integration between Hotmail, SkyDrive [Microsoft's free online storage service] and the Office Web Apps, so you can send, receive and work on a document with others."
Google, of course, offers online editing of documents through Gmail's integration with Google Docs, and the ability to import Microsoft Office documents into Google's online office suite.
Microsoft is increasingly adding to its lineup of Web-based office tools, while offering integration with existing on-premise software installations of Microsoft Office.
New Hotmail features announced this week will be incorporated into the service over the next few months, Microsoft said.
Microsoft promised improvements in the visual quality of Office documents displayed in web browsers, and said it will be easy for users to move back and forth between the Web-based version and the Office software installed on their PCs.
The announcement acknowledges that users may still need to use the packaged software version of Office for "intensive editing tasks."
"If you need to perform intensive editing tasks, you can go from editing the document in your browser with the Office Web Apps to editing it in an Office application on your PC," Microsoft said. "When you're finished, any edits you made to the document on your PC will be automatically saved back into the cloud where you can then keep the document stored for only you to see or share it with others."
Hotmail and Gmail are locked in a battle for second place in the webmail market. Each have more than 40 million users in the United States, with Hotmail claiming a small lead over Gmail. Yahoo still has more than twice as many users as its nearest competitors.
In addition to further Office integration, Microsoft said the new Hotmail will have enhanced security with full-session SSL; smarter junk mail filters and a "Trusted Senders" feature making it easier for users to distinguish between legitimate messages and scams.
Hotmail will also have conversation view – a feature Gmail already has – making it easier to view a single conversation that is spread out over many e-mails.
Hotmail users will be able to send up to 10GB of photos per message, and Microsoft, not surprisingly, is rolling out new mobile features to take advantage of the expanding smartphone market. For example, Microsoft said Hotmail will be optimized for rich mobile browsers and touch screens, while supporting "filters, in-line message previews, HTML messages, offline e-mail viewing, conversation threading, the ability to flag messages, the option to turn header details on or off, and more."
Thursday, May 6, 2010
Wi-Fi key-cracking kits sold in China mean free Internet
Kits that crack WEP and guess WPA keys are popular despite hacking laws
Dodgy salesmen in China are making money from long-known weaknesses in a Wi-Fi encryption standard, by selling network key-cracking kits for the average user.
Wi-Fi USB adapters bundled with a Linux operating system, key-breaking software and a detailed instruction book are being sold online and at China's bustling electronics bazaars. The kits, pitched as a way for users to surf the Web for free, have drawn enough buyers and attention that one Chinese auction site, Taobao.com, had to ban their sale last year.
With one of the "network-scrounging cards," or "ceng wang ka" in Chinese, a user with little technical knowledge can easily steal passwords to get online via Wi-Fi networks owned by other people.
To crack a WEP key, the applications exploit weaknesses in the protocol that have been known for years. For WPA, they capture data being transmitted over the wireless network and target it with a brute-force attack to guess the key.
Security researchers said they did not know of similar kits sold anywhere besides China, even though tutorials on how to crack WEP have been online for years.
Depending on many factors, WEP keys can be extracted in a matter of minutes," Muts said. "I believe the record is around 20 seconds."
The brute-force attacks on WPA encryption are less effective. But while WEP is outdated, many people still use it, especially on home routers, said one security researcher in China. That means an apartment building is bound to have WEP networks for a user to attack.
Dodgy salesmen in China are making money from long-known weaknesses in a Wi-Fi encryption standard, by selling network key-cracking kits for the average user.
Wi-Fi USB adapters bundled with a Linux operating system, key-breaking software and a detailed instruction book are being sold online and at China's bustling electronics bazaars. The kits, pitched as a way for users to surf the Web for free, have drawn enough buyers and attention that one Chinese auction site, Taobao.com, had to ban their sale last year.
With one of the "network-scrounging cards," or "ceng wang ka" in Chinese, a user with little technical knowledge can easily steal passwords to get online via Wi-Fi networks owned by other people.
To crack a WEP key, the applications exploit weaknesses in the protocol that have been known for years. For WPA, they capture data being transmitted over the wireless network and target it with a brute-force attack to guess the key.
Security researchers said they did not know of similar kits sold anywhere besides China, even though tutorials on how to crack WEP have been online for years.
Depending on many factors, WEP keys can be extracted in a matter of minutes," Muts said. "I believe the record is around 20 seconds."
The brute-force attacks on WPA encryption are less effective. But while WEP is outdated, many people still use it, especially on home routers, said one security researcher in China. That means an apartment building is bound to have WEP networks for a user to attack.
Social Web Email CloseDigg Slashdot Fark Stumble Reddit
Microsoft acknowledges fixing internally-found flaws without disclosing details
Microsoft silently patched three vulnerabilities last month, two of them affecting enterprise mission-critical Exchange mail servers, without calling out the bugs in the accompanying advisories, a security expert said today.
Two of the three unannounced vulnerabilities, and the most serious of the trio, were packaged with MS10-024 , an update to Exchange and Windows SMTP Service that Microsoft issued April 13 and tagged as "important," its second-highest threat ranking
According to Ivan Arce, the chief technology officer of Core Security Technologies, Microsoft patched the bugs, but failed to disclose that it had done so.
"They're more important than the [two vulnerabilities] that Microsoft did disclose," said Arce. "That means [system] administrators may end up making the wrong decisions about applying the update. They need that information to assess the risk."
Microsoft silently patched three vulnerabilities last month, two of them affecting enterprise mission-critical Exchange mail servers, without calling out the bugs in the accompanying advisories, a security expert said today.
Two of the three unannounced vulnerabilities, and the most serious of the trio, were packaged with MS10-024 , an update to Exchange and Windows SMTP Service that Microsoft issued April 13 and tagged as "important," its second-highest threat ranking
According to Ivan Arce, the chief technology officer of Core Security Technologies, Microsoft patched the bugs, but failed to disclose that it had done so.
"They're more important than the [two vulnerabilities] that Microsoft did disclose," said Arce. "That means [system] administrators may end up making the wrong decisions about applying the update. They need that information to assess the risk."
example of inheretance clas program
// main class
using System;
using System.Collections.Generic;
using System.Text;
namespace inheretence
{
class Program
{
static void Main(string[] args)
{
woman ee = new woman();
ee.eat();
man rr = new man();
rr.eat();
Console.ReadLine();
}
}
}
// inheretance class
using System;
using System.Collections.Generic;
using System.Text;
namespace inheretence
{
abstract class human
{
public abstract void eat();
{
Console.WriteLine("eatinggggggggggggg");
}
}
class man : human
{
public override void eat()
{
Console.WriteLine("man eating");
}
}
class woman : human
{
public override void eat()
{
Console.WriteLine("woman eating");
}
}
}
using System;
using System.Collections.Generic;
using System.Text;
namespace inheretence
{
class Program
{
static void Main(string[] args)
{
woman ee = new woman();
ee.eat();
man rr = new man();
rr.eat();
Console.ReadLine();
}
}
}
// inheretance class
using System;
using System.Collections.Generic;
using System.Text;
namespace inheretence
{
abstract class human
{
public abstract void eat();
{
Console.WriteLine("eatinggggggggggggg");
}
}
class man : human
{
public override void eat()
{
Console.WriteLine("man eating");
}
}
class woman : human
{
public override void eat()
{
Console.WriteLine("woman eating");
}
}
}
Wednesday, May 5, 2010
Flawed McAfee update paralyzes corporate PCs
Cripples Windows XP machines with endless reboots after critical system file quarantined
A flawed McAfee antivirus update sent enterprise administrators scrambling today as the new signatures quarantined a crucial Windows system file, crippling an unknown number of Windows XP computers, according to messages on the company's support forum.
The forum has since gone offline.
McAfee confirmed it had pushed the faulty update to users earlier today. "McAfee is aware that a number of customers have incurred a false positive error due to incorrect malware alerts on Wednesday, April 21," said company spokesman Joris Evers in an e-mail reply to questions. "The problem occurs with the 5958 virus definition file (DAT) that was released on April 21 at 2:00 P.M. GMT+1 (6:00 A.M. Pacific)."
According to users on McAfee's support forum, today's update flagged Windows' "svchost.exe" file, a generic host process for services that run from other DLLs (dynamic link libraries).
HOW THE F*** do they put a DAT out that kills a *VITAL* system process?" asked Jeff Gerard on one thread. "This is goddamn ridiculous," added Gerard, who identified himself as a senior security administrator with Wawanesa Mutual Insurance Company of Winnipeg, Manitoba, in Canada. "Great work McAfee! GRRRRRRRRRRR."
As of 3:30 p.m. ET, McAfee's support forum was offline, with a message reading "The McAfee Community is experiencing unusually large traffic which may cause slow page loads. We apologize for any inconvenience this may cause."
Both users and McAfee said that the flawed update had crippled Windows XP Service Pack 3 (SP3) machines, but not PCs running Vista or Windows 7 . "Our initial investigation indicates that the error can result in moderate to significant performance issues on systems running Windows XP Service Pack 3," acknowledged Evers.
Affected PCs have displayed a shutdown error or blue error screen, then gone into an endless cycle of rebooting, users claimed.
McAfee reacted by warning users not to download today's update if they haven't already, and by posting recovery instructions and a signature update to suppress the defective one seeded to users earlier. "Apply the EXTRA.DAT to all potentially affected systems as soon as possible," the company recommended. "For systems that have already encountered this issue, start the computer in Safe Mode and apply the EXTRA.DAT. After applying the EXTRA.DAT, restore the affected files from Quarantine." Unfortunately, those instructions and the suppression EXTRA.DAT update file are not currently available, again because McAfee's support site has gone dark.
Instead, users can reach the instructions and EXTRA.DAT file from elsewhere on McAfee's site .
A flawed McAfee antivirus update sent enterprise administrators scrambling today as the new signatures quarantined a crucial Windows system file, crippling an unknown number of Windows XP computers, according to messages on the company's support forum.
The forum has since gone offline.
McAfee confirmed it had pushed the faulty update to users earlier today. "McAfee is aware that a number of customers have incurred a false positive error due to incorrect malware alerts on Wednesday, April 21," said company spokesman Joris Evers in an e-mail reply to questions. "The problem occurs with the 5958 virus definition file (DAT) that was released on April 21 at 2:00 P.M. GMT+1 (6:00 A.M. Pacific)."
According to users on McAfee's support forum, today's update flagged Windows' "svchost.exe" file, a generic host process for services that run from other DLLs (dynamic link libraries).
HOW THE F*** do they put a DAT out that kills a *VITAL* system process?" asked Jeff Gerard on one thread. "This is goddamn ridiculous," added Gerard, who identified himself as a senior security administrator with Wawanesa Mutual Insurance Company of Winnipeg, Manitoba, in Canada. "Great work McAfee! GRRRRRRRRRRR."
As of 3:30 p.m. ET, McAfee's support forum was offline, with a message reading "The McAfee Community is experiencing unusually large traffic which may cause slow page loads. We apologize for any inconvenience this may cause."
Both users and McAfee said that the flawed update had crippled Windows XP Service Pack 3 (SP3) machines, but not PCs running Vista or Windows 7 . "Our initial investigation indicates that the error can result in moderate to significant performance issues on systems running Windows XP Service Pack 3," acknowledged Evers.
Affected PCs have displayed a shutdown error or blue error screen, then gone into an endless cycle of rebooting, users claimed.
McAfee reacted by warning users not to download today's update if they haven't already, and by posting recovery instructions and a signature update to suppress the defective one seeded to users earlier. "Apply the EXTRA.DAT to all potentially affected systems as soon as possible," the company recommended. "For systems that have already encountered this issue, start the computer in Safe Mode and apply the EXTRA.DAT. After applying the EXTRA.DAT, restore the affected files from Quarantine." Unfortunately, those instructions and the suppression EXTRA.DAT update file are not currently available, again because McAfee's support site has gone dark.
Instead, users can reach the instructions and EXTRA.DAT file from elsewhere on McAfee's site .
FBI: Finding criminal data on cell phones and game consoles is tough
FBI says variety of software and limited memory pose challenges
Non-traditional communications devices such as smartphones and game consoles pose a particular problem to law enforcement agencies trying to milk them for forensic data that reveals criminal activity, attendees were told at the 2010 Computer Forensics Show in New York City. "Forensic tools for cell phones are in their infancy," says Stephen Riley, a forensic examiner with the FBI's Computer Analysis and Response Team. "There's lots of different carriers, different phones, different cables – just try to keep up."
Smartphones can communicate via SMS, MMS, mobile e-mail, mobile internet access, VoIP and traditional cellular voice networks, Riley says, making each machine a potential treasure trove of information but also a nightmare maze of possible proprietary technologies to unlock it.
Retrieving SMS messages can depend on the model of phone, the carrier, the time of day, even the country in which the phone is used. SIM cards removed from phones carry potentially useful forensic information, but unless it is associated with a particular phone's PIN, it's inaccessible. Perhaps the personal unlock feature controlled by phone manufacturers could release the data, but that requires knowing the make and model of the phone, he says The ready availability of cell phones is also a problem. Searches of suspects' residences can turn up drawers-full of cell phones that are no longer used but never thrown out. Yet they can demand valuable forensic time.
Game consoles pose a separate problem. They can be used to send e-mail and connect to the Internet but have very little internal memory so whatever is on the drive can be quickly over written and therefore gone forever, he says. "You can take a Wii onto the Internet and it doesn't save sites or browser history," he says. "If you type in a Web address and surf, 10 minutes later there's no record of it."
Non-traditional communications devices such as smartphones and game consoles pose a particular problem to law enforcement agencies trying to milk them for forensic data that reveals criminal activity, attendees were told at the 2010 Computer Forensics Show in New York City. "Forensic tools for cell phones are in their infancy," says Stephen Riley, a forensic examiner with the FBI's Computer Analysis and Response Team. "There's lots of different carriers, different phones, different cables – just try to keep up."
Smartphones can communicate via SMS, MMS, mobile e-mail, mobile internet access, VoIP and traditional cellular voice networks, Riley says, making each machine a potential treasure trove of information but also a nightmare maze of possible proprietary technologies to unlock it.
Retrieving SMS messages can depend on the model of phone, the carrier, the time of day, even the country in which the phone is used. SIM cards removed from phones carry potentially useful forensic information, but unless it is associated with a particular phone's PIN, it's inaccessible. Perhaps the personal unlock feature controlled by phone manufacturers could release the data, but that requires knowing the make and model of the phone, he says The ready availability of cell phones is also a problem. Searches of suspects' residences can turn up drawers-full of cell phones that are no longer used but never thrown out. Yet they can demand valuable forensic time.
Game consoles pose a separate problem. They can be used to send e-mail and connect to the Internet but have very little internal memory so whatever is on the drive can be quickly over written and therefore gone forever, he says. "You can take a Wii onto the Internet and it doesn't save sites or browser history," he says. "If you type in a Web address and surf, 10 minutes later there's no record of it."
Google Apps vs. Microsoft Office
Google may pose strongest long-term threat to Microsoft's dominance
Google Apps or Microsoft Office? That is the question on the minds of many CIOs today
Microsoft has long dominated the e-mail, collaboration and office tools market, and its customer list dwarfs that of Google and all other competitors. But despite the presence of well-established alternatives such as OpenOffice and IBM's Lotus Notes, some industry analysts believe Google may pose the strongest long-term threat to Microsoft's office dominance. "Google is still a wannabe, but they're Google so this is a very strong challenger," says Laura DiDio, lead analyst with Information Technology Intelligence Corp (ITIC).
Why should a business choose Google over Microsoft? Google is inexpensive, at $50 per user per year. Employees are often familiar with Gmail, so user training shouldn't be too burdensome. Outsourcing IT functions to Google lets businesses reduce internal IT expenditures and wasted time maintaining servers and applications. With Google, businesses get the basic productivity tools of e-mail, calendaring, and document creation and editing, as well as a Web site builder, private video sharing and other functions. (See related article, "Google Apps basics".)
Yet even Google has a hard time arguing that its own office tools are just as good as Microsoft's. And customers and analysts agree that Google's support is not on the same level as Microsoft's, which has far more experience dealing with the needs of enterprise customers.
But Google's momentum, and the emergence of cloud computing as a viable alternative to in-house IT systems, has clearly caused Microsoft to change the way it approaches the office market. Microsoft is offering its own online services now, and is being forced to give better pricing to customers who bring up the name of Google as a negotiation tactic.
Rexel, an electrical distributor in France, recently chose to deploy Microsoft Exchange Online instead of Google Apps and was able to get pricing that was nearly identical to Google's $50 per user per year, says CIO Olivier Baldassari
Google Apps or Microsoft Office? That is the question on the minds of many CIOs today
Microsoft has long dominated the e-mail, collaboration and office tools market, and its customer list dwarfs that of Google and all other competitors. But despite the presence of well-established alternatives such as OpenOffice and IBM's Lotus Notes, some industry analysts believe Google may pose the strongest long-term threat to Microsoft's office dominance. "Google is still a wannabe, but they're Google so this is a very strong challenger," says Laura DiDio, lead analyst with Information Technology Intelligence Corp (ITIC).
Why should a business choose Google over Microsoft? Google is inexpensive, at $50 per user per year. Employees are often familiar with Gmail, so user training shouldn't be too burdensome. Outsourcing IT functions to Google lets businesses reduce internal IT expenditures and wasted time maintaining servers and applications. With Google, businesses get the basic productivity tools of e-mail, calendaring, and document creation and editing, as well as a Web site builder, private video sharing and other functions. (See related article, "Google Apps basics".)
Yet even Google has a hard time arguing that its own office tools are just as good as Microsoft's. And customers and analysts agree that Google's support is not on the same level as Microsoft's, which has far more experience dealing with the needs of enterprise customers.
But Google's momentum, and the emergence of cloud computing as a viable alternative to in-house IT systems, has clearly caused Microsoft to change the way it approaches the office market. Microsoft is offering its own online services now, and is being forced to give better pricing to customers who bring up the name of Google as a negotiation tactic.
Rexel, an electrical distributor in France, recently chose to deploy Microsoft Exchange Online instead of Google Apps and was able to get pricing that was nearly identical to Google's $50 per user per year, says CIO Olivier Baldassari
Tuesday, May 4, 2010
Beware the black market rising for IP addresses
IPv4 depletion is happening faster than expected; a black market could jump the price of an Internet presence
Organizations slow to adopt IPv6 take heed: Surging requests for IPv4 addresses are quickly drying up the available store, raising the specter of an IPv4 black market that could dramatically increase the cost of obtaining a presence on today's Internet.
Previous predictions pegged late 2011 as the anticipated date of IPv4 address exhaustion. But a sudden turnaround in the rate of allocation for IPv4 addresses this year has consumed an alarming number of "/8" IPv4 address blocks -- /8 being the unit of allocation to Regional Internet Registries (RIRs).
IPv4 black market: A matter of supply and demand The coming IPv4 shortage has been foreseen for years, but organizations needing an Internet presence -- businesses, educational institutions, government agencies, and the like -- have largely been in denial about the inevitability of IPv4 exhaustion.
At last October's dual celebration of ARPAnet (the Advanced Research Projects Agency Network that preceded the Internet) and the 125th anniversary of event sponsor IEEE, Internet pioneer Vincent Cerf urged immediate IPv6 adoption because Internet growth is not slowing: "We are going to see billions and billions of devices on the Net. The Internet, for its part, has invited many people to contribute content."
In a more recent interview, ARIN's Jimmerson says, "Yes, there was a dip [of IPv4 assignments] in 2009, but 2010 is accelerating. Lots of new applications -- next-gen Wi-Fi, cloud services, and smart grid -- are taking off, and regions such as Asia and South America are coming online rapidly."
IPv4, which uses 32-bit addresses, is capable of supporting 4.3 billion total addresses, but severe fragmentation makes utilization of the full range of IP addresses inefficient. Worse, many consider reclaiming unused IP space a far too complex and expensive undertaking. As such, when the last IPv4 /8 is allocated, new Internet players could find high prices and a black market the only practical means of getting IPv4 addresses.
Organizations slow to adopt IPv6 take heed: Surging requests for IPv4 addresses are quickly drying up the available store, raising the specter of an IPv4 black market that could dramatically increase the cost of obtaining a presence on today's Internet.
Previous predictions pegged late 2011 as the anticipated date of IPv4 address exhaustion. But a sudden turnaround in the rate of allocation for IPv4 addresses this year has consumed an alarming number of "/8" IPv4 address blocks -- /8 being the unit of allocation to Regional Internet Registries (RIRs).
IPv4 black market: A matter of supply and demand The coming IPv4 shortage has been foreseen for years, but organizations needing an Internet presence -- businesses, educational institutions, government agencies, and the like -- have largely been in denial about the inevitability of IPv4 exhaustion.
At last October's dual celebration of ARPAnet (the Advanced Research Projects Agency Network that preceded the Internet) and the 125th anniversary of event sponsor IEEE, Internet pioneer Vincent Cerf urged immediate IPv6 adoption because Internet growth is not slowing: "We are going to see billions and billions of devices on the Net. The Internet, for its part, has invited many people to contribute content."
In a more recent interview, ARIN's Jimmerson says, "Yes, there was a dip [of IPv4 assignments] in 2009, but 2010 is accelerating. Lots of new applications -- next-gen Wi-Fi, cloud services, and smart grid -- are taking off, and regions such as Asia and South America are coming online rapidly."
IPv4, which uses 32-bit addresses, is capable of supporting 4.3 billion total addresses, but severe fragmentation makes utilization of the full range of IP addresses inefficient. Worse, many consider reclaiming unused IP space a far too complex and expensive undertaking. As such, when the last IPv4 /8 is allocated, new Internet players could find high prices and a black market the only practical means of getting IPv4 addresses.
Monday, January 18, 2010
Sampling:& Quantization
Sampling
The process of grabbing the sound into small increments.
These small increments will later form a series of discrete values coded in binary format
Sampling Rate: How often the sound is grabbed, The higher the sampling rate, the more parts are grabbed, the better quality of sound & bigger file size
(Unit: kHz)
Sampling Rate most often used are 22.05 KHz (most common), 44.1KHz (common for audio CD), and 11.025KHz
Quantization
The process of rounding off a continuous value horizontally so that it can be represented by a fixed no of binary bits
Unit: bits (can use 8-bit, 16-bit and so on to quantize sound)
If u choose 8-bit of quantization level to quantize the analog sound, mean the analog sound will be divided into 256 parts.
Similarly, sound quantized at 16-bit divides the waves into 65,536 parts per second, just like 8-bit graphics can convey 256 colors and 16-bits can display 65,536 types of colors.
The larger the bit, the better the sound, the larger the file size
The process of grabbing the sound into small increments.
These small increments will later form a series of discrete values coded in binary format
Sampling Rate: How often the sound is grabbed, The higher the sampling rate, the more parts are grabbed, the better quality of sound & bigger file size
(Unit: kHz)
Sampling Rate most often used are 22.05 KHz (most common), 44.1KHz (common for audio CD), and 11.025KHz
Quantization
The process of rounding off a continuous value horizontally so that it can be represented by a fixed no of binary bits
Unit: bits (can use 8-bit, 16-bit and so on to quantize sound)
If u choose 8-bit of quantization level to quantize the analog sound, mean the analog sound will be divided into 256 parts.
Similarly, sound quantized at 16-bit divides the waves into 65,536 parts per second, just like 8-bit graphics can convey 256 colors and 16-bits can display 65,536 types of colors.
The larger the bit, the better the sound, the larger the file size
Digitization
1.Our world and bodies are analog, functioning in a smooth and continuous flow (analog signal)
eg water current, wind, the flow of bloods etc.
2.The digital world is made of little chunks (digital signal)
Digital Signal
.The representation of info as a series of numbers
.A sequence of discrete values coded in binary format
.Humans deal with analog info
.Humans only perceive digital info when it has been transformed into analog domain
.Computer can only generate and accept info in digital form
.Therefore, we need “Digitization”
Digitization (Devices)
Two devices that allow human and computer interact: ADC and DAC
Analogue-to-Digital Converter (ADC):
Performs the process of converting from analog sound to digital sound
Digital-to-Analog Converter (DAC):
Performs the re-conversion back to analogue sound from digital sound
Found in mm hardware: sound card, audio recorders, graphic cards, video recorder, CD-audio players, printer, monitor, network card etc.
Digitization (Process)
Digitization (The transformation of analog signals into digital signals) requires 2 successive steps:
1.Sampling
2.Quantisation (resolution)
eg water current, wind, the flow of bloods etc.
2.The digital world is made of little chunks (digital signal)
Digital Signal
.The representation of info as a series of numbers
.A sequence of discrete values coded in binary format
.Humans deal with analog info
.Humans only perceive digital info when it has been transformed into analog domain
.Computer can only generate and accept info in digital form
.Therefore, we need “Digitization”
Digitization (Devices)
Two devices that allow human and computer interact: ADC and DAC
Analogue-to-Digital Converter (ADC):
Performs the process of converting from analog sound to digital sound
Digital-to-Analog Converter (DAC):
Performs the re-conversion back to analogue sound from digital sound
Found in mm hardware: sound card, audio recorders, graphic cards, video recorder, CD-audio players, printer, monitor, network card etc.
Digitization (Process)
Digitization (The transformation of analog signals into digital signals) requires 2 successive steps:
1.Sampling
2.Quantisation (resolution)
Types of sound
Sound effects
Message reinforcing: e.g. when discussing topics on nature, sounds of birds, waves etc. can enhance the message
Music
Narration: a voice describes some facts that pertaining to the topic
Voice-overs: Not to be confused with narration, this type of content sound is used in instances where short instructions may be necessary for the user to navigate the multimedia application.
Speech
Singing: Combines characteristics of speech and music
Message reinforcing: e.g. when discussing topics on nature, sounds of birds, waves etc. can enhance the message
Music
Narration: a voice describes some facts that pertaining to the topic
Voice-overs: Not to be confused with narration, this type of content sound is used in instances where short instructions may be necessary for the user to navigate the multimedia application.
Speech
Singing: Combines characteristics of speech and music
Characteristics of Sound (Frequency & Amplitude)
Two important sound characteristics:
frequency and amplitude
Frequency:
The number of cycles a sound wave creates in one second (pitch)
A cycle is measured from one wave peak to another
Unit: Herts (Hz) or cycles per second (cps)
Amplitude:
The volume or loudness of a particular sound
The louder the sound, the higher the amplitude will be
Unit: decibel (dB)
frequency and amplitude
Frequency:
The number of cycles a sound wave creates in one second (pitch)
A cycle is measured from one wave peak to another
Unit: Herts (Hz) or cycles per second (cps)
Amplitude:
The volume or loudness of a particular sound
The louder the sound, the higher the amplitude will be
Unit: decibel (dB)
INTRO TO Sound:
Sound:
.Fluctuations in air pressure (Sound is vibrations in the air) that can be perceived by our ears with some qualitative attribute
.Produced by a source that creates vibration in the air
.The pattern of oscillation is called a waveform
.Fluctuations in air pressure (Sound is vibrations in the air) that can be perceived by our ears with some qualitative attribute
.Produced by a source that creates vibration in the air
.The pattern of oscillation is called a waveform
Software Interrupts
Software in are used by programs to request system services
These interrupts are treated in the same way as the interrupts for the Hardware devises are\
In assembly we useINT instruction to perform such interrupts Syntax: name INT interrupt-number;comments Syntax (simplified): INT interrupt-number Example: INT 21h
These interrupts are used with there functions
Explanation
In order to use I/O operations we use interrupt 21h,
But in order to perform a specific task, like printing a string to a standard output device we have to use its function 09h
Example code
MOV AH 09h
LEA DX, string
INT 21h
These interrupts are treated in the same way as the interrupts for the Hardware devises are\
In assembly we useINT instruction to perform such interrupts Syntax: name INT interrupt-number;comments Syntax (simplified): INT interrupt-number Example: INT 21h
These interrupts are used with there functions
Explanation
In order to use I/O operations we use interrupt 21h,
But in order to perform a specific task, like printing a string to a standard output device we have to use its function 09h
Example code
MOV AH 09h
LEA DX, string
INT 21h
Hardware Interrupt
..When an interrupt is generated by hardware
.It sends a signal request to the processor
.The processor suspends the current tasks it is executing
.Then the control is transferred to the interrupt routine
.Then the interrupt routine performs some I/O operations depending on which generated by the hardware
.Finally the control is transferred back to the previous executing task at the point where it was suspended.
.It sends a signal request to the processor
.The processor suspends the current tasks it is executing
.Then the control is transferred to the interrupt routine
.Then the interrupt routine performs some I/O operations depending on which generated by the hardware
.Finally the control is transferred back to the previous executing task at the point where it was suspended.
How does interrupts work !?
.When the hardware needs service it will request an interrupt.
.A thread is defined as the path of action of software as it executes.
.The execution of the interrupt service routine is called a background thread.
.This thread is created by the hardware interrupt request
.The thread is killed when the interrupt service routine executes the instruction.
.A new thread is created for each interrupt request. It is important to consider each individual request as a separate thread because local variables and registers used in the interrupt service routine are unique and separate from one interrupt event to the next.
.In a multithreaded system we consider the threads as cooperating to perform an overall task.
.When an interrupt is generated
.It sends a signal request to the processor
.The processor suspends the current tasks it is executing
.Then the control is transferred to the interrupt routine
.Then the interrupt routine performs some I/O operations depending on which interrupt function is called or generated by the hardware
.Finally the control is transferred back to the previous executing task at the point
where it was suspended.
.A thread is defined as the path of action of software as it executes.
.The execution of the interrupt service routine is called a background thread.
.This thread is created by the hardware interrupt request
.The thread is killed when the interrupt service routine executes the instruction.
.A new thread is created for each interrupt request. It is important to consider each individual request as a separate thread because local variables and registers used in the interrupt service routine are unique and separate from one interrupt event to the next.
.In a multithreaded system we consider the threads as cooperating to perform an overall task.
.When an interrupt is generated
.It sends a signal request to the processor
.The processor suspends the current tasks it is executing
.Then the control is transferred to the interrupt routine
.Then the interrupt routine performs some I/O operations depending on which interrupt function is called or generated by the hardware
.Finally the control is transferred back to the previous executing task at the point
where it was suspended.
Introduction to Interrupts
Introduction to Interrupts
An interrupt is the automatic transfer of software execution in response to hardware that is asynchronous with the current software execution.
There are 3 main categories of interrupts, Hardware Interrupt Software Interrupt Processor Exception
Interrupts were originally created to allow hardware devices to interrupt the operations of the CPU.
An interrupt is the automatic transfer of software execution in response to hardware that is asynchronous with the current software execution.
There are 3 main categories of interrupts, Hardware Interrupt Software Interrupt Processor Exception
Interrupts were originally created to allow hardware devices to interrupt the operations of the CPU.
Thursday, January 14, 2010
Advantages&Disadvantages of DBMSs
Advantages of DBMSs• Control of data redundancy
• Data consistency
• More information from the same amount of data
• Sharing of data
• Improved data integrity
• Improved security
• Enforcement of standards
• Economy of scale
• Balanced conflicting requirements
• Improved data accessibility and responsiveness
• Increased productivity
• Improved maintenance through data independence
• Increased concurrency
• Improved backup and recovery services
Disadvantages of DBMSs•
Complexity
• Size
• Cost of DBMS
• Additional hardware costs
• Cost of conversion
• Performance
• Higher impact of a failure
• Data consistency
• More information from the same amount of data
• Sharing of data
• Improved data integrity
• Improved security
• Enforcement of standards
• Economy of scale
• Balanced conflicting requirements
• Improved data accessibility and responsiveness
• Increased productivity
• Improved maintenance through data independence
• Increased concurrency
• Improved backup and recovery services
Disadvantages of DBMSs•
Complexity
• Size
• Cost of DBMS
• Additional hardware costs
• Cost of conversion
• Performance
• Higher impact of a failure
Components of the Database Environment
Components of the Database Environment•
Hardware
– Can range from a PC to a network of computers containing secondary storage volumes and hardware processor(s) with associated main memory that are used to support execution of database management system
• Software
– DBMS, operating system, network software (if necessary) and also the application programs.
• Data
– Used by the organization and a description of this data called the schema. The data as discussed above is integrated and shared
– By integrated it is meant that the data is actually a unification of several files with redundancy among files partially eliminated
– By Shared it is meant that individual pieces of data in the database can be shared among different users.
• Procedures
– Instructions and rules that should be applied to the design and use of the database and DBMS.
• People
– The people that participate in the database environment.
– Including
• Application Programmers who are responsible for writing database applications
• End Users are people who interact with database system from workstations and terminals in order view and use data to complete their routine tasks.
• Data Administrator is the person who is responsible for deciding what data is important and should be recorded. This person belongs to senior management level (normally not a technician) and understands what is important for the enterprise. He is also responsible for defining various policies related to data including security policy.
• Database Administrator: This is a technical person responsible for implementing the policies defined by the data administrator. DBA is also responsible for ensuring that the system operates with adequate performance and for providing a variety of technical services.
Hardware
– Can range from a PC to a network of computers containing secondary storage volumes and hardware processor(s) with associated main memory that are used to support execution of database management system
• Software
– DBMS, operating system, network software (if necessary) and also the application programs.
• Data
– Used by the organization and a description of this data called the schema. The data as discussed above is integrated and shared
– By integrated it is meant that the data is actually a unification of several files with redundancy among files partially eliminated
– By Shared it is meant that individual pieces of data in the database can be shared among different users.
• Procedures
– Instructions and rules that should be applied to the design and use of the database and DBMS.
• People
– The people that participate in the database environment.
– Including
• Application Programmers who are responsible for writing database applications
• End Users are people who interact with database system from workstations and terminals in order view and use data to complete their routine tasks.
• Data Administrator is the person who is responsible for deciding what data is important and should be recorded. This person belongs to senior management level (normally not a technician) and understands what is important for the enterprise. He is also responsible for defining various policies related to data including security policy.
• Database Administrator: This is a technical person responsible for implementing the policies defined by the data administrator. DBA is also responsible for ensuring that the system operates with adequate performance and for providing a variety of technical services.
INTRO OF Database Management System & VIEWS
Database Management System (DBMS)• A software system that enables users to define, create, and maintain the database and that provides controlled access to this database.
Views•
Allows each user to have his or her own view of the database.
• A view is essentially some subset of the database.
• Benefits include:
• Reduce complexity;
• Provide a level of security;
• Provide a mechanism to customize the appearance of the database;
• Present a consistent, unchanging picture of the structure of the database, even if the underlying database is changed.
Views•
Allows each user to have his or her own view of the database.
• A view is essentially some subset of the database.
• Benefits include:
• Reduce complexity;
• Provide a level of security;
• Provide a mechanism to customize the appearance of the database;
• Present a consistent, unchanging picture of the structure of the database, even if the underlying database is changed.
Database Approach
Database Approach
• Arose because:
– Definition of data was embedded in application programs, rather than being stored separately and independently.
– No control over access and manipulation of data beyond that imposed by application programs.
• Result:
– the database and Database Management System (DBMS).
Database Approach
• Data definition language (DDL).
– Permits specification of data types, structures and any data constraints.
– All specifications are stored in the database.
• Data manipulation language (DML).
– General enquiry facility (query language) of the data.
• Controlled access to database may include
– A security system.
– An integrity system.
– A concurrency control system.
– A recovery control system.
– A user-accessible catalog.
• A view mechanism.
– Provides users with only the data they want or need to use.
• Arose because:
– Definition of data was embedded in application programs, rather than being stored separately and independently.
– No control over access and manipulation of data beyond that imposed by application programs.
• Result:
– the database and Database Management System (DBMS).
Database Approach
• Data definition language (DDL).
– Permits specification of data types, structures and any data constraints.
– All specifications are stored in the database.
• Data manipulation language (DML).
– General enquiry facility (query language) of the data.
• Controlled access to database may include
– A security system.
– An integrity system.
– A concurrency control system.
– A recovery control system.
– A user-accessible catalog.
• A view mechanism.
– Provides users with only the data they want or need to use.
File-based Systems& Limitations of File-Based Approach
File-based Systems• Collection of application programs that perform services for the end users (e.g. reports).
• Each program defines and manages its own data
• E.g. is a C++ system that accepts and stores data. In such case the sequence in which the fields are recorded is coded in the program, not in the file.
Limitations of File-Based Approach
• Separation and isolation of data
– Each program maintains its own set of data.
– Users of one program may be unaware of potentially useful data held by other
programs.
– Duplication of data
– Same data is held by different programs.
– Wasted space and potentially different values and/or different formats for the same item.
• Duplication of data
– Same data is held by different programs.
– Wasted space and potentially different values and/or different formats for the same item.
• Each program defines and manages its own data
• E.g. is a C++ system that accepts and stores data. In such case the sequence in which the fields are recorded is coded in the program, not in the file.
Limitations of File-Based Approach
• Separation and isolation of data
– Each program maintains its own set of data.
– Users of one program may be unaware of potentially useful data held by other
programs.
– Duplication of data
– Same data is held by different programs.
– Wasted space and potentially different values and/or different formats for the same item.
• Duplication of data
– Same data is held by different programs.
– Wasted space and potentially different values and/or different formats for the same item.
Introducing Database
Introducing Database:
A collection of computerized data files. In simple words it is computerized record keeping.
Examples of Database Applications
• Purchases from the supermarket
• Purchases using your credit card
• Booking a holiday at the travel agents
• Using the local library
• Taking out insurance
• Using the Internet
• Studying at university
Formal definition of Database• Shared collection of logically related data (and a description of this data), designed to meet the information needs of an organization.
• System catalog (metadata) provides description of data to enable program–data independence.
• Logically related data comprises entities, attributes, and relationships of an organization’s information.
A collection of computerized data files. In simple words it is computerized record keeping.
Examples of Database Applications
• Purchases from the supermarket
• Purchases using your credit card
• Booking a holiday at the travel agents
• Using the local library
• Taking out insurance
• Using the Internet
• Studying at university
Formal definition of Database• Shared collection of logically related data (and a description of this data), designed to meet the information needs of an organization.
• System catalog (metadata) provides description of data to enable program–data independence.
• Logically related data comprises entities, attributes, and relationships of an organization’s information.
The Relational Data Model( database)
The Relational Data Model
The Relational Data Model has the relation at its heart, but then a whole series of rules governing keys, relationships, joins, functional dependencies, transitive dependencies, multi-valued dependencies, and modification anomalies.
The RelationThe Relation is the basic element in a relational data model.
A relation is subject to the following rules:
1. Relation (file, table) is a two-dimensional table.
2. Attribute (i.e. field or data item) is a column in the table.
3. Each column in the table has a unique name within that table.
4. Each column is homogeneous. Thus the entries in any column are all of the same type (e.g. age, name, employee-number, etc).
5. Each column has a domain, the set of possible values that can appear in that column.
6. A Tuple (i.e. record) is a row in the table.
7. The order of the rows and columns is not important.
8. Values of a row all relate to some thing or portion of a thing.
9. Repeating groups (collections of logically related attributes that occur multiple times within one record occurrence) are not allowed.
10. Duplicate rows are not allowed (candidate keys are designed to prevent this).
11. Cells must be single-valued (but can be variable length). Single valued means the following:
o Cannot contain multiple values such as 'A1,B2,C3'.
o Cannot contain combined values such as 'ABC-XYZ' where 'ABC' means one thing and 'XYZ' another.
A relation may be expressed using the notation R(A,B,C, ...) where:
• R = the name of the relation.
• (A,B,C, ...) = the attributes within the relation.
• A = the attribute(s) which form the primary key.
Keys
1. A simple key contains a single attribute.
2. A composite key is a key that contains more than one attribute.
3. A candidate key is an attribute (or set of attributes) that uniquely identifies a row. A candidate key must possess the following properties:
o Unique identification - For every row the value of the key must uniquely identify that row.
o Non redundancy - No attribute in the key can be discarded without destroying the property of unique identification.
4. A primary key is the candidate key which is selected as the principal unique identifier. Every relation must contain a primary key. The primary key is usually the key selected to identify a row when the database is physically implemented. For example, a part number is selected instead of a part description.
5. A superkey is any set of attributes that uniquely identifies a row. A superkey differs from a candidate key in that it does not require the non redundancy property.
6. A foreign key is an attribute (or set of attributes) that appears (usually) as a non key attribute in one relation and as a primary key attribute in another relation. I say usually because it is possible for a foreign key to also be the whole or part of a primary key:
o A many-to-many relationship can only be implemented by introducing an intersection or link table which then becomes the child in two one-to-many relationships. The intersection table therefore has a foreign key for each of its parents, and its primary key is a composite of both foreign keys.
o A one-to-one relationship requires that the child table has no more than one occurrence for each parent, which can only be enforced by letting the foreign key also serve as the primary key.
7. A semantic or natural key is a key for which the possible values have an obvious meaning to the user or the data. For example, a semantic primary key for a COUNTRY entity might contain the value 'USA' for the occurrence describing the United States of America. The value 'USA' has meaning to the user.
8. A technical or surrogate or artificial key is a key for which the possible values have no obvious meaning to the user or the data. These are used instead of semantic keys for any of the following reasons:
o When the value in a semantic key is likely to be changed by the user, or can have duplicates. For example, on a PERSON table it is unwise to use PERSON_NAME as the key as it is possible to have more than one person with the same name, or the name may change such as through marriage.
o When none of the existing attributes can be used to guarantee uniqueness. In this case adding an attribute whose value is generated by the system, e.g from a sequence of numbers, is the only way to provide a unique value. Typical examples would be ORDER_ID and INVOICE_ID. The value '12345' has no meaning to the user as it conveys nothing about the entity to which it relates.
9. A key functionally determines the other attributes in the row, thus it is always a determinant.
10. Note that the term 'key' in most DBMS engines is implemented as an index which does not allow duplicate entries.
Relationships
One table (relation) may be linked with another in what is known as a relationship. Relationships may be built into the database structure to facilitate the operation of relational joins at runtime.
1. A relationship is between two tables in what is known as a one-to-many or parent-child or master-detail relationship where an occurrence on the 'one' or 'parent' or 'master' table may have any number of associated occurrences on the 'many' or 'child' or 'detail' table. To achieve this the child table must contain fields which link back the primary key on the parent table. These fields on the child table are known as a foreign key, and the parent table is referred to as the foreign table (from the viewpoint of the child).
2. It is possible for a record on the parent table to exist without corresponding records on the child table, but it should not be possible for an entry on the child table to exist without a corresponding entry on the parent table.
3. A child record without a corresponding parent record is known as an orphan.
4. It is possible for a table to be related to itself. For this to be possible it needs a foreign key which points back to the primary key. Note that these two keys cannot be comprised of exactly the same fields otherwise the record could only ever point to itself.
5. A table may be the subject of any number of relationships, and it may be the parent in some and the child in others.
6. Some database engines allow a parent table to be linked via a candidate key, but if this were changed it could result in the link to the child table being broken.
7. Some database engines allow relationships to be managed by rules known as referential integrity or foreign key restraints. These will prevent entries on child tables from being created if the foreign key does not exist on the parent table, or will deal with entries on child tables when the entry on the parent table is updated or deleted.
Determinant and Dependent
The terms determinant and dependent can be described as follows:
1. The expression X Y means 'if I know the value of X, then I can obtain the value of Y' (in a table or somewhere).
2. In the expression X Y, X is the determinant and Y is the dependent attribute.
3. The value X determines the value of Y.
4. The value Y depends on the value of X.
Functional Dependencies (FD)
A functional dependency can be described as follows:
1. An attribute is functionally dependent if its value is determined by another attribute which is a key.
2. That is, if we know the value of one (or several) data items, then we can find the value of another (or several).
3. Functional dependencies are expressed as X Y, where X is the determinant and Y is the functionally dependent attribute.
4. If A (B,C) then A B and A C.
5. If (A,B) C, then it is not necessarily true that A C and B C.
6. If A B and B A, then A and B are in a 1-1 relationship.
7. If A B then for A there can only ever be one value for B.
Transitive Dependencies (TD)
A transitive dependency can be described as follows:
1. An attribute is transitively dependent if its value is determined by another attribute which is not a key.
2. If X Y and X is not a key then this is a transitive dependency.
3. A transitive dependency exists when A B C but NOT A C.
Multi-Valued Dependencies (MVD)A multi-valued dependency can be
described as follows:
1. A table involves a multi-valued dependency if it may contain multiple values for an entity.
2. A multi-valued dependency may arise as a result of enforcing 1st normal form.
3. X Y, ie X multi-determines Y, when for each value of X we can have more than one value of Y.
4. If A B and A C then we have a single attribute A which multi-determines two other independent attributes, B and C.
5. If A (B,C) then we have an attribute A which multi-determines a set of associated attributes, B and C.
Types of Relational Join
A JOIN is a method of creating a result set that combines rows from two or more tables (relations). When comparing the contents of two tables the following conditions may occur:
• Every row in one relation has a match in the other relation.
• Relation R1 contains rows that have no match in relation R2.
• Relation R2 contains rows that have no match in relation R1.
INNER joins contain only matches. OUTER joins may contain mismatches as well.
Inner Join
This is sometimes known as a simple join. It returns all rows from both tables where there is a match. If there are rows in R1 which do not have matches in R2, those rows will not be listed. There are two possible ways of specifying this type of join:
SELECT * FROM R1, R2 WHERE R1.r1_field = R2.r2_field;
SELECT * FROM R1 INNER JOIN R2 ON R1.field = R2.r2_field
If the fields to be matched have the same names in both tables then the ON condition, as in:
ON R1.fieldname = R2.fieldname
ON (R1.field1 = R2.field1 AND R1.field2 = R2.field2)
can be replaced by the shorter USING condition, as in:
USING fieldname
USING (field1, field2)
Natural Join
A natural join is based on all columns in the two tables that have the same name. It is semantically equivalent to an INNER JOIN or a LEFT JOIN with a USING clause that names all columns that exist in both tables.
SELECT * FROM R1 NATURAL JOIN R2
The alternative is a keyed join which includes an ON or USING condition.
Left [Outer] Join
Returns all the rows from R1 even if there are no matches in R2. If there are no matches in R2 then the R2 values will be shown as null.
SELECT * FROM R1 LEFT [OUTER] JOIN R2 ON R1.field = R2.field
Right [Outer] Join
Returns all the rows from R2 even if there are no matches in R1. If there are no matches in R1 then the R1 values will be shown as null.
SELECT * FROM R1 RIGHT [OUTER] JOIN R2 ON R1.field = R2.field
Full [Outer] Join
Returns all the rows from both tables even if there are no matches in one of the tables. If there are no matches in one of the tables then its values will be shown as null.
SELECT * FROM R1 FULL [OUTER] JOIN R2 ON R1.field = R2.field
Self Join
This joins a table to itself. This table appears twice in the FROM clause and is followed by table aliases that qualify column names in the join condition.
SELECT a.field1, b.field2 FROM R1 a, R1 b WHERE a.field = b.field
Cross Join
This type of join is rarely used as it does not have a join condition, so every row of R1 is joined to every row of R2. For example, if both tables contain 100 rows the result will be 10,000 rows. This is sometimes known as a cartesian product and can be specified in either one of the following ways:
SELECT * FROM R1 CROSS JOIN R2
SELECT * FROM R1, R2
The Relational Data Model has the relation at its heart, but then a whole series of rules governing keys, relationships, joins, functional dependencies, transitive dependencies, multi-valued dependencies, and modification anomalies.
The RelationThe Relation is the basic element in a relational data model.
A relation is subject to the following rules:
1. Relation (file, table) is a two-dimensional table.
2. Attribute (i.e. field or data item) is a column in the table.
3. Each column in the table has a unique name within that table.
4. Each column is homogeneous. Thus the entries in any column are all of the same type (e.g. age, name, employee-number, etc).
5. Each column has a domain, the set of possible values that can appear in that column.
6. A Tuple (i.e. record) is a row in the table.
7. The order of the rows and columns is not important.
8. Values of a row all relate to some thing or portion of a thing.
9. Repeating groups (collections of logically related attributes that occur multiple times within one record occurrence) are not allowed.
10. Duplicate rows are not allowed (candidate keys are designed to prevent this).
11. Cells must be single-valued (but can be variable length). Single valued means the following:
o Cannot contain multiple values such as 'A1,B2,C3'.
o Cannot contain combined values such as 'ABC-XYZ' where 'ABC' means one thing and 'XYZ' another.
A relation may be expressed using the notation R(A,B,C, ...) where:
• R = the name of the relation.
• (A,B,C, ...) = the attributes within the relation.
• A = the attribute(s) which form the primary key.
Keys
1. A simple key contains a single attribute.
2. A composite key is a key that contains more than one attribute.
3. A candidate key is an attribute (or set of attributes) that uniquely identifies a row. A candidate key must possess the following properties:
o Unique identification - For every row the value of the key must uniquely identify that row.
o Non redundancy - No attribute in the key can be discarded without destroying the property of unique identification.
4. A primary key is the candidate key which is selected as the principal unique identifier. Every relation must contain a primary key. The primary key is usually the key selected to identify a row when the database is physically implemented. For example, a part number is selected instead of a part description.
5. A superkey is any set of attributes that uniquely identifies a row. A superkey differs from a candidate key in that it does not require the non redundancy property.
6. A foreign key is an attribute (or set of attributes) that appears (usually) as a non key attribute in one relation and as a primary key attribute in another relation. I say usually because it is possible for a foreign key to also be the whole or part of a primary key:
o A many-to-many relationship can only be implemented by introducing an intersection or link table which then becomes the child in two one-to-many relationships. The intersection table therefore has a foreign key for each of its parents, and its primary key is a composite of both foreign keys.
o A one-to-one relationship requires that the child table has no more than one occurrence for each parent, which can only be enforced by letting the foreign key also serve as the primary key.
7. A semantic or natural key is a key for which the possible values have an obvious meaning to the user or the data. For example, a semantic primary key for a COUNTRY entity might contain the value 'USA' for the occurrence describing the United States of America. The value 'USA' has meaning to the user.
8. A technical or surrogate or artificial key is a key for which the possible values have no obvious meaning to the user or the data. These are used instead of semantic keys for any of the following reasons:
o When the value in a semantic key is likely to be changed by the user, or can have duplicates. For example, on a PERSON table it is unwise to use PERSON_NAME as the key as it is possible to have more than one person with the same name, or the name may change such as through marriage.
o When none of the existing attributes can be used to guarantee uniqueness. In this case adding an attribute whose value is generated by the system, e.g from a sequence of numbers, is the only way to provide a unique value. Typical examples would be ORDER_ID and INVOICE_ID. The value '12345' has no meaning to the user as it conveys nothing about the entity to which it relates.
9. A key functionally determines the other attributes in the row, thus it is always a determinant.
10. Note that the term 'key' in most DBMS engines is implemented as an index which does not allow duplicate entries.
Relationships
One table (relation) may be linked with another in what is known as a relationship. Relationships may be built into the database structure to facilitate the operation of relational joins at runtime.
1. A relationship is between two tables in what is known as a one-to-many or parent-child or master-detail relationship where an occurrence on the 'one' or 'parent' or 'master' table may have any number of associated occurrences on the 'many' or 'child' or 'detail' table. To achieve this the child table must contain fields which link back the primary key on the parent table. These fields on the child table are known as a foreign key, and the parent table is referred to as the foreign table (from the viewpoint of the child).
2. It is possible for a record on the parent table to exist without corresponding records on the child table, but it should not be possible for an entry on the child table to exist without a corresponding entry on the parent table.
3. A child record without a corresponding parent record is known as an orphan.
4. It is possible for a table to be related to itself. For this to be possible it needs a foreign key which points back to the primary key. Note that these two keys cannot be comprised of exactly the same fields otherwise the record could only ever point to itself.
5. A table may be the subject of any number of relationships, and it may be the parent in some and the child in others.
6. Some database engines allow a parent table to be linked via a candidate key, but if this were changed it could result in the link to the child table being broken.
7. Some database engines allow relationships to be managed by rules known as referential integrity or foreign key restraints. These will prevent entries on child tables from being created if the foreign key does not exist on the parent table, or will deal with entries on child tables when the entry on the parent table is updated or deleted.
Determinant and Dependent
The terms determinant and dependent can be described as follows:
1. The expression X Y means 'if I know the value of X, then I can obtain the value of Y' (in a table or somewhere).
2. In the expression X Y, X is the determinant and Y is the dependent attribute.
3. The value X determines the value of Y.
4. The value Y depends on the value of X.
Functional Dependencies (FD)
A functional dependency can be described as follows:
1. An attribute is functionally dependent if its value is determined by another attribute which is a key.
2. That is, if we know the value of one (or several) data items, then we can find the value of another (or several).
3. Functional dependencies are expressed as X Y, where X is the determinant and Y is the functionally dependent attribute.
4. If A (B,C) then A B and A C.
5. If (A,B) C, then it is not necessarily true that A C and B C.
6. If A B and B A, then A and B are in a 1-1 relationship.
7. If A B then for A there can only ever be one value for B.
Transitive Dependencies (TD)
A transitive dependency can be described as follows:
1. An attribute is transitively dependent if its value is determined by another attribute which is not a key.
2. If X Y and X is not a key then this is a transitive dependency.
3. A transitive dependency exists when A B C but NOT A C.
Multi-Valued Dependencies (MVD)A multi-valued dependency can be
described as follows:
1. A table involves a multi-valued dependency if it may contain multiple values for an entity.
2. A multi-valued dependency may arise as a result of enforcing 1st normal form.
3. X Y, ie X multi-determines Y, when for each value of X we can have more than one value of Y.
4. If A B and A C then we have a single attribute A which multi-determines two other independent attributes, B and C.
5. If A (B,C) then we have an attribute A which multi-determines a set of associated attributes, B and C.
Types of Relational Join
A JOIN is a method of creating a result set that combines rows from two or more tables (relations). When comparing the contents of two tables the following conditions may occur:
• Every row in one relation has a match in the other relation.
• Relation R1 contains rows that have no match in relation R2.
• Relation R2 contains rows that have no match in relation R1.
INNER joins contain only matches. OUTER joins may contain mismatches as well.
Inner Join
This is sometimes known as a simple join. It returns all rows from both tables where there is a match. If there are rows in R1 which do not have matches in R2, those rows will not be listed. There are two possible ways of specifying this type of join:
SELECT * FROM R1, R2 WHERE R1.r1_field = R2.r2_field;
SELECT * FROM R1 INNER JOIN R2 ON R1.field = R2.r2_field
If the fields to be matched have the same names in both tables then the ON condition, as in:
ON R1.fieldname = R2.fieldname
ON (R1.field1 = R2.field1 AND R1.field2 = R2.field2)
can be replaced by the shorter USING condition, as in:
USING fieldname
USING (field1, field2)
Natural Join
A natural join is based on all columns in the two tables that have the same name. It is semantically equivalent to an INNER JOIN or a LEFT JOIN with a USING clause that names all columns that exist in both tables.
SELECT * FROM R1 NATURAL JOIN R2
The alternative is a keyed join which includes an ON or USING condition.
Left [Outer] Join
Returns all the rows from R1 even if there are no matches in R2. If there are no matches in R2 then the R2 values will be shown as null.
SELECT * FROM R1 LEFT [OUTER] JOIN R2 ON R1.field = R2.field
Right [Outer] Join
Returns all the rows from R2 even if there are no matches in R1. If there are no matches in R1 then the R1 values will be shown as null.
SELECT * FROM R1 RIGHT [OUTER] JOIN R2 ON R1.field = R2.field
Full [Outer] Join
Returns all the rows from both tables even if there are no matches in one of the tables. If there are no matches in one of the tables then its values will be shown as null.
SELECT * FROM R1 FULL [OUTER] JOIN R2 ON R1.field = R2.field
Self Join
This joins a table to itself. This table appears twice in the FROM clause and is followed by table aliases that qualify column names in the join condition.
SELECT a.field1, b.field2 FROM R1 a, R1 b WHERE a.field = b.field
Cross Join
This type of join is rarely used as it does not have a join condition, so every row of R1 is joined to every row of R2. For example, if both tables contain 100 rows the result will be 10,000 rows. This is sometimes known as a cartesian product and can be specified in either one of the following ways:
SELECT * FROM R1 CROSS JOIN R2
SELECT * FROM R1, R2
Wednesday, January 13, 2010
FIFO Dynamics
FIFO Dynamics
As you recall, the FIFO passes the data from the producer to the consumer. In general, the rates at which data are produced and consumed can vary dynamically. Humans do not enter data into a keyboard at a constant rate.
Even printers require more time to print color graphics versus black and white text. Let tp be the time (in sec) between calls to PutFifo, and rp be the arrival rate (producer rate in bytes/sec) into the system. Similarly, let tg be the time (in sec) between calls to GetFifo, and rg be the service rate (consumerrate in bytes/sec) out of the system.
rg=1/tg
rp=1/tp
If the minimum time between calls to PutFifo is greater than the maximum time between calls to GetFifo,
min tp > max tg
the other hand, if the time between calls to PutFifo becomes less than the time between calls to GetFifo because either
• the arrival rate temporarily increases
• the service rate temporarily decreases
then information will be collected in the FIFO. For example, a person might type very fast for a while followed by long pause. The FIFO could be used to capture without loss all the data as it comes in very fast. Clearly on average the system must be able to process the data (the consumer thread) at least as fast as the average rate at which the data arrives (producer thread). If the average producer rate is larger than the average consumer rate
rp > rg
then the FIFO will eventually overflow no matter how large the FIFO. If the producer rate is temporarily high, and that causes the FIFO to become full, then this problem can be solved by increasing the FIFO size.
There is fundamental difference between an empty error and a full error. Consider the application of using a FIFO between your computer and its printer. This is a good idea because the computer can temporarily generate data to be printed at a very high rate followed by long pauses. The printer is like a
turtle. It can print at a slow but steady rate (e.g., 10 characters/sec.) The computer will put a byte into the FIFO that it wants printed. The printer will get a byte out of the FIFO when it is ready to print another character. A full error occurs when the computer calls PutFifo at too fast a rate. A full error is serious,
because if ignored data will be lost. On the other hand, an empty error occurs when the printer is ready to print but the computer has nothing in mind. An empty error is not serious, because in this case the printer just sits there doing nothing.
As you recall, the FIFO passes the data from the producer to the consumer. In general, the rates at which data are produced and consumed can vary dynamically. Humans do not enter data into a keyboard at a constant rate.
Even printers require more time to print color graphics versus black and white text. Let tp be the time (in sec) between calls to PutFifo, and rp be the arrival rate (producer rate in bytes/sec) into the system. Similarly, let tg be the time (in sec) between calls to GetFifo, and rg be the service rate (consumerrate in bytes/sec) out of the system.
rg=1/tg
rp=1/tp
If the minimum time between calls to PutFifo is greater than the maximum time between calls to GetFifo,
min tp > max tg
the other hand, if the time between calls to PutFifo becomes less than the time between calls to GetFifo because either
• the arrival rate temporarily increases
• the service rate temporarily decreases
then information will be collected in the FIFO. For example, a person might type very fast for a while followed by long pause. The FIFO could be used to capture without loss all the data as it comes in very fast. Clearly on average the system must be able to process the data (the consumer thread) at least as fast as the average rate at which the data arrives (producer thread). If the average producer rate is larger than the average consumer rate
rp > rg
then the FIFO will eventually overflow no matter how large the FIFO. If the producer rate is temporarily high, and that causes the FIFO to become full, then this problem can be solved by increasing the FIFO size.
There is fundamental difference between an empty error and a full error. Consider the application of using a FIFO between your computer and its printer. This is a good idea because the computer can temporarily generate data to be printed at a very high rate followed by long pauses. The printer is like a
turtle. It can print at a slow but steady rate (e.g., 10 characters/sec.) The computer will put a byte into the FIFO that it wants printed. The printer will get a byte out of the FIFO when it is ready to print another character. A full error occurs when the computer calls PutFifo at too fast a rate. A full error is serious,
because if ignored data will be lost. On the other hand, an empty error occurs when the printer is ready to print but the computer has nothing in mind. An empty error is not serious, because in this case the printer just sits there doing nothing.
Two pointer/counter FIFO implementation
Two pointer/counter FIFO implementation
The other method to determine if a FIFO is empty or full is to implement a counter. In the following code, Size contains the number of bytes currently stored in the FIFO.
The advantage of implementing the counter is that FIFO 1/4 full and 3/4 full conditions are easier to implement. If you were studying the behavior of a system it might be informative to measure the current Size as a function of time.
/* Pointer,counter implementation of the FIFO */
#define FifoSize 10 /* Number of 8 bit data in the Fifo */
char *PutPt; /* Pointer of where to put next */
char *GetPt; /* Pointer of where to get next */
unsigned char Size; /* Number of elements currently in the FIFO */
/* FIFO is empty if Size=0 */
/* FIFO is full if Size=FifoSize */
char Fifo[FifoSize]; /* The statically allocated fifo data */
void InitFifo(void) { char SaveSP;
asm(" tpa\n staa %SaveSP\n sei"); /* make atomic, entering critical*/
PutPt=GetPt=&Fifo[0]; /* Empty when Size==0 */
Size=0;
asm(" ldaa %SaveSP\n tap"); /* end critical section */
}
int PutFifo (char data) { char SaveSP;
if (Size == FifoSize ) {
return(0);} /* Failed, fifo was full */
else{
asm(" tpa\n staa %SaveSP\n sei"); /* make atomic, entering critical*/
Size++;
*(PutPt++)=data; /* put data into fifo */
if (PutPt == &Fifo[FifoSize]) PutPt = &Fifo[0]; /* Wrap */
asm(" ldaa %SaveSP\n tap"); /* end critical section */
return(-1); /* Successful */
}
}
int GetFifo (char *datapt) { char SaveSP;
if (Size == 0 ){
return(0);} /* Empty if Size=0 */
else{
asm(" tpa\n staa %SaveSP\n sei"); /* make atomic, entering critical*/
*datapt=*(GetPt++); Size--;
if (GetPt == &Fifo[FifoSize]) GetPt = &Fifo[0];
asm(" ldaa %SaveSP\n tap"); /* end critical section */
return(-1); }
}
Program 5.18. C language routines to implement a two pointer with counter FIFO.
To check for FIFO full, the above PutFifo routine simply compares Size to the maximum allowed
value. If the FIFO is already full then the routine is exited without saving the data. With this
implementation a FIFO with 10 allocated bytes can actually hold 10 data points.
To check for FIFO empty, the following GetFifo routine simply checks to see if Size equals 0.
If Size is zero at the start of the routine, then GetFifo returns with the "empty" condition signified.
The other method to determine if a FIFO is empty or full is to implement a counter. In the following code, Size contains the number of bytes currently stored in the FIFO.
The advantage of implementing the counter is that FIFO 1/4 full and 3/4 full conditions are easier to implement. If you were studying the behavior of a system it might be informative to measure the current Size as a function of time.
/* Pointer,counter implementation of the FIFO */
#define FifoSize 10 /* Number of 8 bit data in the Fifo */
char *PutPt; /* Pointer of where to put next */
char *GetPt; /* Pointer of where to get next */
unsigned char Size; /* Number of elements currently in the FIFO */
/* FIFO is empty if Size=0 */
/* FIFO is full if Size=FifoSize */
char Fifo[FifoSize]; /* The statically allocated fifo data */
void InitFifo(void) { char SaveSP;
asm(" tpa\n staa %SaveSP\n sei"); /* make atomic, entering critical*/
PutPt=GetPt=&Fifo[0]; /* Empty when Size==0 */
Size=0;
asm(" ldaa %SaveSP\n tap"); /* end critical section */
}
int PutFifo (char data) { char SaveSP;
if (Size == FifoSize ) {
return(0);} /* Failed, fifo was full */
else{
asm(" tpa\n staa %SaveSP\n sei"); /* make atomic, entering critical*/
Size++;
*(PutPt++)=data; /* put data into fifo */
if (PutPt == &Fifo[FifoSize]) PutPt = &Fifo[0]; /* Wrap */
asm(" ldaa %SaveSP\n tap"); /* end critical section */
return(-1); /* Successful */
}
}
int GetFifo (char *datapt) { char SaveSP;
if (Size == 0 ){
return(0);} /* Empty if Size=0 */
else{
asm(" tpa\n staa %SaveSP\n sei"); /* make atomic, entering critical*/
*datapt=*(GetPt++); Size--;
if (GetPt == &Fifo[FifoSize]) GetPt = &Fifo[0];
asm(" ldaa %SaveSP\n tap"); /* end critical section */
return(-1); }
}
Program 5.18. C language routines to implement a two pointer with counter FIFO.
To check for FIFO full, the above PutFifo routine simply compares Size to the maximum allowed
value. If the FIFO is already full then the routine is exited without saving the data. With this
implementation a FIFO with 10 allocated bytes can actually hold 10 data points.
To check for FIFO empty, the following GetFifo routine simply checks to see if Size equals 0.
If Size is zero at the start of the routine, then GetFifo returns with the "empty" condition signified.
First In First Out Queue
Introduction to FIFO’s
As we saw earlier, the first in first out circular queue (FIFO) is quite useful for implementing a buffered I/O interface. It can be used for both buffered input and buffered output. The order preserving data structure temporarily saves data created by the source (producer) before it is processed by the sink (consumer). The class of FIFO’s studied in this section will be statically allocated global structures.
Because they are global variables, it means they will exist permanently and can be carefully shared by more than one program. The advantage of using a FIFO structure for a data flow problem is that we can decouple the producer and consumer threads. Without the FIFO we would have to produce 1 piece of data, then
process it, produce another piece of data, then process it. With the FIFO, the producer thread can continue to produce data without having to wait for the consumer to finish processing the previous data. This decoupling can significantly improve system performance.
You have probably already experienced the convenience of FIFO’s. For example, you can continue to type another commands into the DOS command interpreter while it is still processing a previous command. The ASCII codes are put (calls PutFifo) in a FIFO whenever you hit the key. When the DOS command interpreter is free it calls GetFifo for more keyboard data to process. A FIFO is also used
when you ask the computer to print a file. Rather than waiting for the actual printing to occur character by character, the print command will PUT the data in a FIFO. Whenever the printer is free, it will GET data from the FIFO. The advantage of the FIFO is it allows you to continue to use your computer while the printing occurs in the background. To implement this magic of background printing we will need interrupts.
There are many producer/consumer applications. In the following table the processes on the left are producers that create or input data, while the processes on the right are consumers which process or output data.
You have probably already experienced the convenience of FIFO’s. For example, you can continue to type another commands into the DOS command interpreter while it is still processing a previous command. The ASCII codes are put (calls PutFifo) in a FIFO whenever you hit the key. When the
DOS command interpreter is free it calls GetFifo for more keyboard data to process. A FIFO is also used when you ask the computer to print a file. Rather than waiting for the actual printing to occur character by character, the print command will PUT the data in a FIFO. Whenever the printer is free, it will GET data from the FIFO. The advantage of the FIFO is it allows you to continue to use your computer while the
printing occurs in the background. To implement this magic of background printing we will need interrupts.
There are many producer/consumer applications. In the following table the processes on the left are producers that create or input data, while the processes on the right are consumers which process or output data.
As we saw earlier, the first in first out circular queue (FIFO) is quite useful for implementing a buffered I/O interface. It can be used for both buffered input and buffered output. The order preserving data structure temporarily saves data created by the source (producer) before it is processed by the sink (consumer). The class of FIFO’s studied in this section will be statically allocated global structures.
Because they are global variables, it means they will exist permanently and can be carefully shared by more than one program. The advantage of using a FIFO structure for a data flow problem is that we can decouple the producer and consumer threads. Without the FIFO we would have to produce 1 piece of data, then
process it, produce another piece of data, then process it. With the FIFO, the producer thread can continue to produce data without having to wait for the consumer to finish processing the previous data. This decoupling can significantly improve system performance.
You have probably already experienced the convenience of FIFO’s. For example, you can continue to type another commands into the DOS command interpreter while it is still processing a previous command. The ASCII codes are put (calls PutFifo) in a FIFO whenever you hit the key. When the DOS command interpreter is free it calls GetFifo for more keyboard data to process. A FIFO is also used
when you ask the computer to print a file. Rather than waiting for the actual printing to occur character by character, the print command will PUT the data in a FIFO. Whenever the printer is free, it will GET data from the FIFO. The advantage of the FIFO is it allows you to continue to use your computer while the printing occurs in the background. To implement this magic of background printing we will need interrupts.
There are many producer/consumer applications. In the following table the processes on the left are producers that create or input data, while the processes on the right are consumers which process or output data.
You have probably already experienced the convenience of FIFO’s. For example, you can continue to type another commands into the DOS command interpreter while it is still processing a previous command. The ASCII codes are put (calls PutFifo) in a FIFO whenever you hit the key. When the
DOS command interpreter is free it calls GetFifo for more keyboard data to process. A FIFO is also used when you ask the computer to print a file. Rather than waiting for the actual printing to occur character by character, the print command will PUT the data in a FIFO. Whenever the printer is free, it will GET data from the FIFO. The advantage of the FIFO is it allows you to continue to use your computer while the
printing occurs in the background. To implement this magic of background printing we will need interrupts.
There are many producer/consumer applications. In the following table the processes on the left are producers that create or input data, while the processes on the right are consumers which process or output data.
When to use interrupts
When to use interrupts
The following factors should be considered when deciding the most appropriate mechanism to synchronize hardware and software. One should not always use gadfly because one is too lazy tO implement the complexities of interrupts. On the other hand, one should not always use interrupts because they are fun and exciting.
isition&control
The following factors should be considered when deciding the most appropriate mechanism to synchronize hardware and software. One should not always use gadfly because one is too lazy tO implement the complexities of interrupts. On the other hand, one should not always use interrupts because they are fun and exciting.
isition&control
Interrupt Service Routines
The interrupt service routine (ISR) is the software module that is executed when the hardware requests an interrupt. From the last section, we see that there may be one large ISR that handles all requests (polled interrupts), or many small ISR's specific for each potential source of interrupt (vectored interrupts). The design of the interrupt service routine requires careful consideration of many factors that will be discussed in this chapter. When an interrupt is requested (and the device is armed and the I bit is one), the microcomputer will service an interrupt:
1) the execution of the main program is suspended (the current instruction is finished),
2) the interrupt service routine, or background thread is executed,
3) the main program is resumed when the interrupt service routine executes iret .
When the microcomputer accepts an interrupt request, it will automatically save the execution state of the main thread by pushing all its registers on the stack. After the ISR provides the necessary service it will execute a iret instruction. This instruction pulls the registers from the stack, which returns control to the main program. Execution of the main program will then continue with the exact stack and register values that existed before the interrupt. Although interrupt handlers can allocate, access then deallocate local variables, parameter passing between threads must be implemented using global memory variables. Global variables are also equired if an interrupt thread wishes to pass information to itself, e.g., from one interrupt instance to another. The execution of the main program is called the foreground thread, and the executions of interrupt service routines are called background threads.
Interrupt definition
Interrupt definition
An interrupt is the automatic transfer of software execution in response to hardware that is asynchronous with the current software execution. The hardware can either be an external I/O device (like a keyboard or printer) or an internal event (like an op code fault, or a periodic timer.) When the hardware needs service (busy to done state transition) it will request an interrupt. A thread is defined as the path of
action of software as it executes. The execution of the interrupt service routine is called a background thread. This thread is created by the hardware interrupt request and is killed when the interrupt service routine executes the iret instruction. A new thread is created for each interrupt request. It is important to consider each individual request as a separate thread because local variables and registers used in the interrupt service routine are unique and separate from one interrupt event to the next. In a multithreaded system we consider the threads as cooperating to perform an overall task. Consequently we will develop ways for the threads to communicat and synchronize with each other. Most embedded systems have a single common overall goal. On the other hand general-purpose computers can have multiple unrelated functions to perform. A process is also defined as the action of software as it executes. The difference is processes do not necessarily cooperate towards a common shared goal. The software has dynamic control over aspects of the interrupt request sequence. First, each potential interrupt source has a separate arm bit that the software can activate or deactivate. The software will set the arm bits for those devices it wishes to accept interrupts from, and will deactivate the arm bits
within those devices from which interrupts are not to be allowed. In other words it uses the arm bits to individually select which devices will and which devices will not request interrupts. The second aspect that the software controls is the interrupt enable bit, I, which is in the status register (SR). The software can
enable all armed interrupts by setting I=1 (sti), or it can disable all interrupts by setting I=0 (cli). The disabled interrupt state (I=0) does not dismiss the interrupt requests, rather it postpones them until a later time, when the software deems it convenient to handle the requests. We will pay special attention to these
enable/disable software actions. In particular we will need to disable interrupts when executing nonreentrant code but disabling interrupts will have the effect of increasing the response time of software. There are two general methods with which we configure external hardware so that it can request an interrupt. The first method is a shared negative logic level-active request like IRQ . All the devices
that need to request interrupts have an open collector negative logic interrupt request line. The hardware requests service by pulling the interrupt request IRQ line low. The line over the IRQ signifies negative logic. In other words, an interrupt is requested when IRQ is zero. Because the request lines are open
collector, a pull up resistor is needed to make IRQ high when no devices need service.
Normally these interrupt requests share the same interrupt vector. This means whichever device requests an
interrupt, the same interrupt service routine is executed. Therefore the interrupt service routine must first
determine which device requested the interrupt.
The original IBM-PC had only 8 dedicated edge-triggered interrupt lines, and the current PC I/O bus only has 15. This small number can be a serious limitation in a computer system with many I/O devices.
Observation: Microcomputer systems running in expanded mode often use shared negative logic
level-active interrupts for their external I/O devices.
Observation: Microcomputer systems running in single chip mode often use dedicated edgetriggered
interrupts for their I/O devices.
Observation: The number of interrupting devices on a system using dedicated edge-triggered
interrupts is limited when compared to a system using shared negative logic level-active interrupts.
Observation: Most Motorola microcomputers support both shared negative logic and dedicated edge-triggered interrupts.
An interrupt is the automatic transfer of software execution in response to hardware that is asynchronous with the current software execution. The hardware can either be an external I/O device (like a keyboard or printer) or an internal event (like an op code fault, or a periodic timer.) When the hardware needs service (busy to done state transition) it will request an interrupt. A thread is defined as the path of
action of software as it executes. The execution of the interrupt service routine is called a background thread. This thread is created by the hardware interrupt request and is killed when the interrupt service routine executes the iret instruction. A new thread is created for each interrupt request. It is important to consider each individual request as a separate thread because local variables and registers used in the interrupt service routine are unique and separate from one interrupt event to the next. In a multithreaded system we consider the threads as cooperating to perform an overall task. Consequently we will develop ways for the threads to communicat and synchronize with each other. Most embedded systems have a single common overall goal. On the other hand general-purpose computers can have multiple unrelated functions to perform. A process is also defined as the action of software as it executes. The difference is processes do not necessarily cooperate towards a common shared goal. The software has dynamic control over aspects of the interrupt request sequence. First, each potential interrupt source has a separate arm bit that the software can activate or deactivate. The software will set the arm bits for those devices it wishes to accept interrupts from, and will deactivate the arm bits
within those devices from which interrupts are not to be allowed. In other words it uses the arm bits to individually select which devices will and which devices will not request interrupts. The second aspect that the software controls is the interrupt enable bit, I, which is in the status register (SR). The software can
enable all armed interrupts by setting I=1 (sti), or it can disable all interrupts by setting I=0 (cli). The disabled interrupt state (I=0) does not dismiss the interrupt requests, rather it postpones them until a later time, when the software deems it convenient to handle the requests. We will pay special attention to these
enable/disable software actions. In particular we will need to disable interrupts when executing nonreentrant code but disabling interrupts will have the effect of increasing the response time of software. There are two general methods with which we configure external hardware so that it can request an interrupt. The first method is a shared negative logic level-active request like IRQ . All the devices
that need to request interrupts have an open collector negative logic interrupt request line. The hardware requests service by pulling the interrupt request IRQ line low. The line over the IRQ signifies negative logic. In other words, an interrupt is requested when IRQ is zero. Because the request lines are open
collector, a pull up resistor is needed to make IRQ high when no devices need service.
Normally these interrupt requests share the same interrupt vector. This means whichever device requests an
interrupt, the same interrupt service routine is executed. Therefore the interrupt service routine must first
determine which device requested the interrupt.
The original IBM-PC had only 8 dedicated edge-triggered interrupt lines, and the current PC I/O bus only has 15. This small number can be a serious limitation in a computer system with many I/O devices.
Observation: Microcomputer systems running in expanded mode often use shared negative logic
level-active interrupts for their external I/O devices.
Observation: Microcomputer systems running in single chip mode often use dedicated edgetriggered
interrupts for their I/O devices.
Observation: The number of interrupting devices on a system using dedicated edge-triggered
interrupts is limited when compared to a system using shared negative logic level-active interrupts.
Observation: Most Motorola microcomputers support both shared negative logic and dedicated edge-triggered interrupts.
Monday, January 11, 2010
Parallel Computer Architecture
Parallel computer architectures are now going to real applications! This fact is demonstrated by the large number of application areas covered in this book (see section on applications of parallel computer architectures). The applications range from image analysis to quantum mechanics and databases. Still, the use of parallel architectures poses serious problems and requires the development of new techniques and tools. This book is a collection of best papers presented at the first workshop on two major research activities at the Universitat Erlangen-N/imberg and Technische Universitat Munchen. At both universities, more than 100 resarchers are working in the field of multiprocessor systems and network configurations and methods and tools for parallel systems. Indeed, the German Science Foundation (Deutsche Forschungsgemeinschaft ) has been sponsoring the projects under grant numbers SFB 182 and SFB 342. Research grants in the form of a Sonderforschungsbereich are given to selected German Universities in portions of three years following a thoroughful reviewing process. The overall duration of such a research grant is restricted to 12 years. The initiative at Erlangen-Nurnberg was started in 1987 and has been headed since this time by Prof. Dr. H. Wedekind. Work at TU-Miinchen began in 1990, head of this initiative is Prof. Dr A. Bode. The authors of this book are grateful to the Deutsche Forschungsgemeinsehaft for its continuing support in the field of research on parallel processing. The first section of the book is devoted to hardware apects of parallel systems. Here, a number of basic problems have to be solved. Latency and bandwidths of interconnection networks are a bottleneck for parallel process communicatlon. Optoelectronic media, discussed in this section, could change this fact. The sealabillty of parallel hardware is demonstrated with the multiprocessor system MEMSY based on the concept of distributed shared memory. Scalable parallel systems need fault tolerance mechanisms to garantee reliable system behaviour even in the presence of defects in parts of the system. An approach to fault tolerance for scalable parallel systems is discussed in this section. The next section is devoted to performance aspects of parallel systems. Analytical models for performance prediction are presented as well as a new hardware monitor system together with the evaluation software. Tools for the automatic parallelization of existing applications are a dream, but not yet reality for the user of parallel systems. Different aspects for automatic treatment of parallel apphcations are covered in the next section on architectures and tools for paral]elizatlon. Dynamic lead balancing is an application transparent mechanism of the operating system to guarantee equal lead on the elements of a multiprocessor system. Randomizod shared memory is one possible implementation of a virtual shared memory based on distributed memory hardware.
Interface ActionListener
Interface ActionListener.
public interface ActionListener
The ActionListener interface is an addition to the Portlet interface. If an object wishes to receive action events in the portlet, this interface has to be implemented additionally to the Portlet interface.
public interface ActionEvent
extends Event
An ActionEvent is sent by the portlet container when an HTTP request is received that is associated with an action.
static int ACTION_PERFORMED
Event identifier indicating that portlet request has been received that one or more actions associated with it.
PortletAction getAction()
Deprecated. Use getActionString() instead
java.lang.String getActionString()
Returns the action string that this action event carries.
ACTION_PERFORMED
public static final int ACTION_PERFORMED
Event identifier indicating that portlet request has been received that one or more actions associated with it. Each action will result in a separate event being fired.
An event with this id is fired when an action has to be performe
void actionPerformed(ActionEvent event)
Notifies this listener that the action which the listener is watching for has been performed
Method Detail
actionPerformed
public void actionPerformed(ActionEvent event)
throws PortletException
Notifies this listener that the action which the listener is watching for has been performed.
Parameters:
event - the action event
Throws:
PortletException - if the listener has trouble fulfilling the request
public interface ActionListener
The ActionListener interface is an addition to the Portlet interface. If an object wishes to receive action events in the portlet, this interface has to be implemented additionally to the Portlet interface.
public interface ActionEvent
extends Event
An ActionEvent is sent by the portlet container when an HTTP request is received that is associated with an action.
static int ACTION_PERFORMED
Event identifier indicating that portlet request has been received that one or more actions associated with it.
PortletAction getAction()
Deprecated. Use getActionString() instead
java.lang.String getActionString()
Returns the action string that this action event carries.
ACTION_PERFORMED
public static final int ACTION_PERFORMED
Event identifier indicating that portlet request has been received that one or more actions associated with it. Each action will result in a separate event being fired.
An event with this id is fired when an action has to be performe
void actionPerformed(ActionEvent event)
Notifies this listener that the action which the listener is watching for has been performed
Method Detail
actionPerformed
public void actionPerformed(ActionEvent event)
throws PortletException
Notifies this listener that the action which the listener is watching for has been performed.
Parameters:
event - the action event
Throws:
PortletException - if the listener has trouble fulfilling the request
INTRO OF Data representation &Immutability IN JAVA
Data representation changes in scientific applications. Simple example: represent a point using Cartesian or polar coordinates. Polynomials (coefficents vs. point-value), matrices (sparse vs. dense).
Immutability. An immutable data type is a data type such that the value of an object never changes once constructed. Examples: Complex and String. When you pass a String to a method, you don't have to worry about that method changing the sequence of characters in the String. On the other hand, when you pass an array to a method, the method is free to change the elements of the array.
Immutable data types have numerous advantages. they are easier to use, harder to misuse, easier to debug code that uses immutable types, easier to guarantee that the class variables remain in a consistent state (since they never change after construction), no need for copy constructor, are thread-safe, work well as keys in symbol table, don't need to be defensively copied when used as an instance variable in another class. Disadvantage: separate object for each value.
Josh Block, a Java API architect, advises that "Classes should be immutable unless there's a very good reason to make them mutable....If a class cannot be made immutable, you should still limit its mutability as much as possible."
Give example where function changes value of some Complex object, which leaves the invoking function with a variable whose value it cannot rely upon.
mutable immutable
------------------------------------
Counter Complex
MovingCharge Charge
Draw String
array Vector
java.util.Date primitive types
Picture wrapper types
Final. Java provides language support to enforce immutability. When you declare a variable to be final, you are promising to assign it a value only once, either in an initializer or in the constructor. It is a compile-time error to modify the value of a final variable. public class Complex {
private final double re;
private final double im;
public Complex(double real, double imag) {
re = real;
im = imag;
}
// compile-time error
public void plus(Complex b) {
re = this.re + b.re; // oops, overwrites invoking object's value
im = this.im + b.re; // compile-time error since re and im are final
return new Complex(re, im);
}
}
It is good style to use the modifier final with instance variables whose values never change.
Serves as documentation that the value does not change.
Prevents accidental changes.
Makes programs easier to debug, since it's easier to keep track of the state: initialized at construction time and never changes.
Mutable instance variables. If the value of a final instance variable is mutable, the value of that instance variable (the reference to an object) will never change - it will always refer to the same object. However, the value of the object itself can change. For example, in Java, arrays are mutable objects: if you have an final instance variable that is an array, you can't change the array (e.g., to change its length), but you can change the individual array elements.
This creates a potential mutable hole in an otherwise immutable data type. For example, the following implementation of a Vector is mutable. public final class Vector {
private final int N;
private final double[] coords;
public Vector(double[] a) {
N = a.length;
coords = a;
}
...
}
A client program can create a Vector by specifying the entries in an array, and then change the elements of the Vector from (3, 4) to (0, 4) after construction (thereby bypassing the public API). double[] a = { 3.0, 4.0 };
Vector vector = new Vector(a);
StdOut.println(vector.magnitude()); // 5.0
a[0] = 0.0; // bypassing the public API
StdOut.println(vector.magnitude()); // 4.0
Defensive copy. To guarantee immutability of a data type that includes an instance variable of a mutable type, we perform a defensive copy. By creating a local copy of the array, we ensure that any change the client makes to the original array has no effect on the object. public final class Vector {
private final int N;
private final double[] coords;
public Vector(double[] a) {
N = a.length;
// defensive copy
coords = new double[N];
for (int i = 0; i < N; i++) {
coords[i] = a[i];
}
}
...
}
Program Vector.java encapsulates an immutable array.
Global constants. The final modifier is also widely used to specify local or global constants. For example, the following appears in Java's Math library. public static final double E = 2.7182818284590452354;
public static final double PI = 3.14159265358979323846;
If the variables were declared public, a client could wreak havoc by re-assigning Math.PI = 1.0; Since Math.PI is declared to be private, such an attempt would be flagged as a compile-time error.
Immutability. An immutable data type is a data type such that the value of an object never changes once constructed. Examples: Complex and String. When you pass a String to a method, you don't have to worry about that method changing the sequence of characters in the String. On the other hand, when you pass an array to a method, the method is free to change the elements of the array.
Immutable data types have numerous advantages. they are easier to use, harder to misuse, easier to debug code that uses immutable types, easier to guarantee that the class variables remain in a consistent state (since they never change after construction), no need for copy constructor, are thread-safe, work well as keys in symbol table, don't need to be defensively copied when used as an instance variable in another class. Disadvantage: separate object for each value.
Josh Block, a Java API architect, advises that "Classes should be immutable unless there's a very good reason to make them mutable....If a class cannot be made immutable, you should still limit its mutability as much as possible."
Give example where function changes value of some Complex object, which leaves the invoking function with a variable whose value it cannot rely upon.
mutable immutable
------------------------------------
Counter Complex
MovingCharge Charge
Draw String
array Vector
java.util.Date primitive types
Picture wrapper types
Final. Java provides language support to enforce immutability. When you declare a variable to be final, you are promising to assign it a value only once, either in an initializer or in the constructor. It is a compile-time error to modify the value of a final variable. public class Complex {
private final double re;
private final double im;
public Complex(double real, double imag) {
re = real;
im = imag;
}
// compile-time error
public void plus(Complex b) {
re = this.re + b.re; // oops, overwrites invoking object's value
im = this.im + b.re; // compile-time error since re and im are final
return new Complex(re, im);
}
}
It is good style to use the modifier final with instance variables whose values never change.
Serves as documentation that the value does not change.
Prevents accidental changes.
Makes programs easier to debug, since it's easier to keep track of the state: initialized at construction time and never changes.
Mutable instance variables. If the value of a final instance variable is mutable, the value of that instance variable (the reference to an object) will never change - it will always refer to the same object. However, the value of the object itself can change. For example, in Java, arrays are mutable objects: if you have an final instance variable that is an array, you can't change the array (e.g., to change its length), but you can change the individual array elements.
This creates a potential mutable hole in an otherwise immutable data type. For example, the following implementation of a Vector is mutable. public final class Vector {
private final int N;
private final double[] coords;
public Vector(double[] a) {
N = a.length;
coords = a;
}
...
}
A client program can create a Vector by specifying the entries in an array, and then change the elements of the Vector from (3, 4) to (0, 4) after construction (thereby bypassing the public API). double[] a = { 3.0, 4.0 };
Vector vector = new Vector(a);
StdOut.println(vector.magnitude()); // 5.0
a[0] = 0.0; // bypassing the public API
StdOut.println(vector.magnitude()); // 4.0
Defensive copy. To guarantee immutability of a data type that includes an instance variable of a mutable type, we perform a defensive copy. By creating a local copy of the array, we ensure that any change the client makes to the original array has no effect on the object. public final class Vector {
private final int N;
private final double[] coords;
public Vector(double[] a) {
N = a.length;
// defensive copy
coords = new double[N];
for (int i = 0; i < N; i++) {
coords[i] = a[i];
}
}
...
}
Program Vector.java encapsulates an immutable array.
Global constants. The final modifier is also widely used to specify local or global constants. For example, the following appears in Java's Math library. public static final double E = 2.7182818284590452354;
public static final double PI = 3.14159265358979323846;
If the variables were declared public, a client could wreak havoc by re-assigning Math.PI = 1.0; Since Math.PI is declared to be private, such an attempt would be flagged as a compile-time error.
defination of Encapsulation in Java ..Access control.,Getters and setters.
Encapsulation in Java. Java provides language support for information hiding. When we declare an instance variable (or method) as private, this means that the client (code written in another module) cannot directly access that instance variable (or method). The client can only access the API through the public methods and constructors. Programmer can modify the implementation of private methods (or use different instance variables) with the comfort that no client will be directly affected.
Program Counter.java implements a counter, e.g., for an electronic voting machine. It encapsulates a single integer to ensure that it can only get incremented by one at at time and to ensure that it never goes negative. The goal of data abstraction is to restrict which operations you can perform. Can ensure that data type value always remains in a consistent state. Can add logging capability to hit(), e.g., to print timestamp of each vote. In the 2000 presidential election, Al Gore received negative 16,022 votes on an electronic voting machine in Volusia County, Florida. The counter variable was not properly encapsulated in the voting machine software!
Access control. Java provides a mechanism for access control to prevent the use of some variable or method in one part of a program from direct access in another. We have been careful to define all of our instance variables with the private access modifier. This means that they cannot be directly accessed from another class, thereby encapsulating the data type. For this reason, we always use private as the access modifier for our instance variables and recommend that you do the same. If you use public then you will greatly limit any opportunity to modify the class over time. Client programs may rely on your public variable in thousands of places, and you will not be able to remove it without breaking dependent code.
Getters and setters. A data type should not have public instance variables. You should obey this rule not just in letter, but also in spirit. Novice programmers are often tempted to include get() and set() methods for each instance variable, to read and write its value.
Complex a = new Complex(1.0, 2.0);
Complex b = new Complex(3.0, 4.0);
// violates spirit of encapsulation
Complex c = new Complex(0.0, 0.0);
c.setRe(a.re() + b.re());
c.setIm(a.im() + b.im());
// better design
Complex a = new Complex(1.0, 2.0);
Complex b = new Complex(3.0, 4.0);
Complex c = a.plus(b);
The purpose of encapsulation is not just to hide the data, but to hide design decisions which are subject to change. In other words, the client should tell an object what to do, rather than asking an object about its state (get()), making a decision, and then telling it how to do it (set()). Usually it's better design to not have the get() and set() methods. When a get() method is warranted, try to avoid including a set() method
Program Counter.java implements a counter, e.g., for an electronic voting machine. It encapsulates a single integer to ensure that it can only get incremented by one at at time and to ensure that it never goes negative. The goal of data abstraction is to restrict which operations you can perform. Can ensure that data type value always remains in a consistent state. Can add logging capability to hit(), e.g., to print timestamp of each vote. In the 2000 presidential election, Al Gore received negative 16,022 votes on an electronic voting machine in Volusia County, Florida. The counter variable was not properly encapsulated in the voting machine software!
Access control. Java provides a mechanism for access control to prevent the use of some variable or method in one part of a program from direct access in another. We have been careful to define all of our instance variables with the private access modifier. This means that they cannot be directly accessed from another class, thereby encapsulating the data type. For this reason, we always use private as the access modifier for our instance variables and recommend that you do the same. If you use public then you will greatly limit any opportunity to modify the class over time. Client programs may rely on your public variable in thousands of places, and you will not be able to remove it without breaking dependent code.
Getters and setters. A data type should not have public instance variables. You should obey this rule not just in letter, but also in spirit. Novice programmers are often tempted to include get() and set() methods for each instance variable, to read and write its value.
Complex a = new Complex(1.0, 2.0);
Complex b = new Complex(3.0, 4.0);
// violates spirit of encapsulation
Complex c = new Complex(0.0, 0.0);
c.setRe(a.re() + b.re());
c.setIm(a.im() + b.im());
// better design
Complex a = new Complex(1.0, 2.0);
Complex b = new Complex(3.0, 4.0);
Complex c = a.plus(b);
The purpose of encapsulation is not just to hide the data, but to hide design decisions which are subject to change. In other words, the client should tell an object what to do, rather than asking an object about its state (get()), making a decision, and then telling it how to do it (set()). Usually it's better design to not have the get() and set() methods. When a get() method is warranted, try to avoid including a set() method
Designing APIs
Designing APIs. Often the most important and most challenging step in building software is designing the APIs. In many ways, designing good programs is more challenging that writing the code itself. Takes practice, careful deliberation, and many iterations.
Specification problem. Document the API in English. Clearly articulate behavior for all possible inputs, including side effects. "Write to specification." Difficult problem. Many bugs introduced because programmer didn't correctly understand description of API. See booksite for information on automatic documentation using Javadoc.
Wide interfaces. "API should do one thing and do it well." "APIs should be as small as possible, but no smaller." "When in doubt, leave it out." (It's easy to add methods to an existing API, but you can never remove them without breaking existing clients.) APIs with lots of bloat are known as wide interfaces. Supply all necessary operations, but no more. Try to make methods orthogonal in functionality. No need for a method in Complex that adds three complex numbers since there is a method that adds two. The Math library includes methods for sin(), cos(), and tan(), but not sec().
Java libraries tend to have wide interfaces (some designed by pros, some by committee). Sometimes this seems to be the right thing, e.g., String. Although, sometimes you end up with poorly designed APIs that you have to live with forever.
Deprecated methods. Sometimes you end up with deprecated methods that are no longer fully supported, but you still need to keep them or break backward compatibility. Once Java included a method Character.isSpace(), programmers wrote programs that relied on its behavior. Later, they wanted to change the method to support additional Unicode whitespace characters. Can't change the behavior of isSpace() or that would break many programs. Instead, add a new method Character.isWhiteSpace() and "deprecate" the old method. The API is now more confusing than needed.
Almost all methods in java.util.Date are deprecated in favor of java.util.GregorianCalendar.
Backward compatibility. The need for backward compatibility shapes much of the way things are done today (from operating systems to programming languages to ...). [Insert a story.]
Standards. It is easy to understand why writing to an API is so important by considering other domains. Fax machines, radio, MPEG-4, MP3 files, PDF files, HTML, etc. Simpler to use a common standard. Lack of incompatibilities enables business opportunities that would otherwise be impossible. One of the challenges of writing software is making it portable so that it works on a variety of operating systems including Windows, OS X, and Linux. Java Virtual Machine enables portability of Java across platforms.
Specification problem. Document the API in English. Clearly articulate behavior for all possible inputs, including side effects. "Write to specification." Difficult problem. Many bugs introduced because programmer didn't correctly understand description of API. See booksite for information on automatic documentation using Javadoc.
Wide interfaces. "API should do one thing and do it well." "APIs should be as small as possible, but no smaller." "When in doubt, leave it out." (It's easy to add methods to an existing API, but you can never remove them without breaking existing clients.) APIs with lots of bloat are known as wide interfaces. Supply all necessary operations, but no more. Try to make methods orthogonal in functionality. No need for a method in Complex that adds three complex numbers since there is a method that adds two. The Math library includes methods for sin(), cos(), and tan(), but not sec().
Java libraries tend to have wide interfaces (some designed by pros, some by committee). Sometimes this seems to be the right thing, e.g., String. Although, sometimes you end up with poorly designed APIs that you have to live with forever.
Deprecated methods. Sometimes you end up with deprecated methods that are no longer fully supported, but you still need to keep them or break backward compatibility. Once Java included a method Character.isSpace(), programmers wrote programs that relied on its behavior. Later, they wanted to change the method to support additional Unicode whitespace characters. Can't change the behavior of isSpace() or that would break many programs. Instead, add a new method Character.isWhiteSpace() and "deprecate" the old method. The API is now more confusing than needed.
Almost all methods in java.util.Date are deprecated in favor of java.util.GregorianCalendar.
Backward compatibility. The need for backward compatibility shapes much of the way things are done today (from operating systems to programming languages to ...). [Insert a story.]
Standards. It is easy to understand why writing to an API is so important by considering other domains. Fax machines, radio, MPEG-4, MP3 files, PDF files, HTML, etc. Simpler to use a common standard. Lack of incompatibilities enables business opportunities that would otherwise be impossible. One of the challenges of writing software is making it portable so that it works on a variety of operating systems including Windows, OS X, and Linux. Java Virtual Machine enables portability of Java across platforms.
Sunday, January 10, 2010
String processing.
String processing. The program CommentStripper.java reads in a Java (or C++) program from standard input, removes all comments, and prints the result to standard output. This would be useful as part of a Java compiler. It removes /* */ and // style comments using a 5 state finite state automaton. It is meant to illustrate the power of DFAs, but to properly strip Java comments, you would need a few more states to handle extra cases, e.g., quoted string literals like s = "/***//*". The picture below is courtesy of David Eppstein.
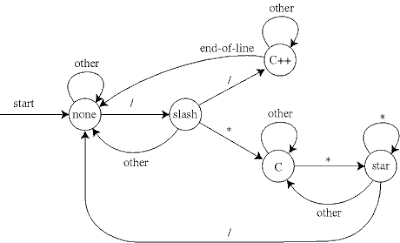

DEFINATION & DESCRIPTION OF Finite state automata.

Finite state automata. A deterministic finite state automaton (DFA) is, perhaps, the simplest type of machine that is still interesting to study. Many of its important properties carry over to more complicated machines. So, before we hope to understand these more complicated machines, we first study DFAs. However, it is an enormously useful practical abstraction because DFAs still retain sufficient flexibility to perform interesting tasks, yet the hardware requirements for building them are relatively minimal. DFAs are widely used in text editors for pattern matching, in compilers for lexical analysis, in web browsers for html parsing, and in operating systems for graphical user interfaces. They also serve as the control unit in many physical systems including: vending machines, elevators, automatic traffic signals, and computer microprocessors. Also network protocol stacks and old VCR clocks. They also play a key role in natural language processing and machine learning.
A DFA captures the basic elements of an abstract machine: it reads in a string, and depending on the input and the way the machine was designed, it outputs true or false. A DFA is always is one of N states, which we name 0 through N-1. Each state is labeled true or false. The DFA begins in a distinguished state called the start state. As the input characters are read in one at a time, the DFA changes from one state to another in a prespecified way. The new state is completely determined by the current state and the character just read in. When the input is exhausted, the DFA outputs true or false according to the label of the state it is currently in.
UPPER PICTURE is an example of a DFA that accepts binary strings that are multiples of 3. For example, the machine rejects 1101 since 1101 in binary is 13 in decimal, which is not divisible by 3. On the other hand, the machine accepts 1100 since it is 12 in decimal.
Abstract machines
Abstract machines. Modern computers are capable of performing a wide variety of computations. An abstract machine reads in an input string, and, depending on the input, outputs true (accept), outputs false (reject), or gets stuck in an infinite loop and outputs nothing. We say that a machine recognizes a particular language, if it outputs true for any input string in the language and false otherwise. The artificial restriction to such decision problems is purely for notational convenience. Virtually all computational problems can be recast as language recognition problems. For example, to determine whether an integer 97 is prime, we can ask whether 97 is in the language consisting of all primes {2, 3, 5, 7, 13, ... } or to determine the decimal expansion of the mathematical constant π we can ask whether 7 is the 100th digit of π and so on.
We would like to be able to formally compare different classes of abstract machines in order to address questions like Is a Mac more powerful than a PC? Can Java do more things than C++? To accomplish this, we define a notion of power. We say that machine A is at least as powerful as machine B if machine A can be "programmed'" to recognize all of the languages that B can. Machine A is more powerful than B, if in addition, it can be programmed to recognize at least one additional language. Two machines are equivalent if they can be programmed to recognize precisely the same set of languages. Using this definition of power, we will classify several fundamental machines. Naturally, we are interested in designing the most powerful computer, i.e., the one that can solve the widest range of language recognition problems. Note that our notion of power does not say anything about how fast a computation can be done. Instead, it reflects a more fundamental notion of whether or not it is even possible to perform some computation in a finite number of steps.
We would like to be able to formally compare different classes of abstract machines in order to address questions like Is a Mac more powerful than a PC? Can Java do more things than C++? To accomplish this, we define a notion of power. We say that machine A is at least as powerful as machine B if machine A can be "programmed'" to recognize all of the languages that B can. Machine A is more powerful than B, if in addition, it can be programmed to recognize at least one additional language. Two machines are equivalent if they can be programmed to recognize precisely the same set of languages. Using this definition of power, we will classify several fundamental machines. Naturally, we are interested in designing the most powerful computer, i.e., the one that can solve the widest range of language recognition problems. Note that our notion of power does not say anything about how fast a computation can be done. Instead, it reflects a more fundamental notion of whether or not it is even possible to perform some computation in a finite number of steps.
DEFNATION OF Turing machines
Turing machines are the most general automata. They consist of a finite set of states and an infinite tape which contains the input and is used to read and write symbols during the computation. Since Turing machines can leave symbols on their tape at the end of the computation, they can be viewed as computing functions: the partial recursive functions. Despite the simplicity of these automata, any algorithm that can be implemented on a computer can be modeled by some Turing machine.
Turing machines are used in the characterization of the complexity of problems. The complexity of a problem is determined by the efficiency of the best algorithm that solves it. Measures of an algorithm's efficiency are the amount of time or space that a Turing machine requires to implement the algorithm. A computation's time is the number of configurations involved in that computation, and its space corresponds to the number of positions on its tape that were used.
Turing machines are used in the characterization of the complexity of problems. The complexity of a problem is determined by the efficiency of the best algorithm that solves it. Measures of an algorithm's efficiency are the amount of time or space that a Turing machine requires to implement the algorithm. A computation's time is the number of configurations involved in that computation, and its space corresponds to the number of positions on its tape that were used.
DEFINATION ABOUT Automata Theory
Automata theory is a further step in abstracting your attention away from any
particular kind of computer or particular programming language. In automata theory
we consider a mathematical model of computing. Such a model strips the computational
machinery—the “programming language”—down to the bare minimum, so that it’s easy
to manipulate these theoretical machines (there are several such models, for different purposes, as you’ll soon see) mathematically to prove things about their capabilities.
For the most part, these mathematical models are not used for practical programming
problems. Real programming languages are much more convenient to use. But the very
flexibility that makes real languages easier to use also makes them harder to talk about in a formal way. The stripped-down theoretical machines are designed to be examined
mathematically.
What’s a mathematical model? You’ll see one shortly, called a “finite-state machine.”
The point of this study is that the mathematical models are, in some important ways,
to real computers and real programming languages. What this means is that
any problem that can be solved on a real computer can be solved using these models,and vice versa. Anything we can prove about the models sheds light on the real problems of computer programming as well.
The questions asked in automata theory include these: Are there any problems that
no computer can solve, no matter how much time and memory it has? Is it possible to
PROVE that a particular computer program will actually solve a particular problem? If a computer can use two different external storage devices (disks or tapes) at the same time,does that extend the range of problems it can solve compared to a machine with only one such device?
There is also a larger question lurking in the background of automata theory: Does
the human mind solve problems in the same way that a computer does? Are people
subject to the same limitations as computers? Automata theory does not actually answer this question, but the insights of automata theory can be helpful in trying to work out an answer. We’ll have more to say about this in the chapter on artificial intelligence
particular kind of computer or particular programming language. In automata theory
we consider a mathematical model of computing. Such a model strips the computational
machinery—the “programming language”—down to the bare minimum, so that it’s easy
to manipulate these theoretical machines (there are several such models, for different purposes, as you’ll soon see) mathematically to prove things about their capabilities.
For the most part, these mathematical models are not used for practical programming
problems. Real programming languages are much more convenient to use. But the very
flexibility that makes real languages easier to use also makes them harder to talk about in a formal way. The stripped-down theoretical machines are designed to be examined
mathematically.
What’s a mathematical model? You’ll see one shortly, called a “finite-state machine.”
The point of this study is that the mathematical models are, in some important ways,
to real computers and real programming languages. What this means is that
any problem that can be solved on a real computer can be solved using these models,and vice versa. Anything we can prove about the models sheds light on the real problems of computer programming as well.
The questions asked in automata theory include these: Are there any problems that
no computer can solve, no matter how much time and memory it has? Is it possible to
PROVE that a particular computer program will actually solve a particular problem? If a computer can use two different external storage devices (disks or tapes) at the same time,does that extend the range of problems it can solve compared to a machine with only one such device?
There is also a larger question lurking in the background of automata theory: Does
the human mind solve problems in the same way that a computer does? Are people
subject to the same limitations as computers? Automata theory does not actually answer this question, but the insights of automata theory can be helpful in trying to work out an answer. We’ll have more to say about this in the chapter on artificial intelligence
Subscribe to:
Comments (Atom)